MySQL
一、MySQL 基础
1. 什么是 MySQL?
MySQL是一个开源的关系型数据库管理系统(RDBMS, Relational Database Management System),它使用结构化查询语言(Structured Query Language, SQL)进行数据库的创建、管理和操作。MySQL 是由瑞典公司 MySQL AB 开发的,现在最终成为 Oracle 公司的产品。
关系主要指键,主键唯一标识,外键建立表与表之间的关系。
RDBMS 通常有 ACID 特性:
- 原子性 (Atomicity):事务中的所有操作要么
全部完成,要么全部不完成 -回滚
比如银行转账,1️⃣A账户扣款,2️⃣B账户加款。
如果中途失败了,没有事务支持的 MyISAM 就会出现 A 账户的款也扣了,B 账户又没加,钱凭空消失了。
p.s.InnoDB 会把整个转账操作作为一个事务,要是中途失败了,就回滚所有操作重来。
- 一致性 (Consistency):数据库只会从一个
有效状态转换到另一个有效状态
还是转账,数据库会有一个约束条件:A账户余额 + B账户余额 = 常量。
无论转账过程中发生什么错误,这个约束条件都必须成立。这才叫有效状态。
- 隔离性 (Isolation):
并发执行的事务互不干扰
当A在给B转账时,C只会看到A账户扣款前的余额;等A的转账事务提交后,C才能看到最新的余额。不可能出现C看到一个中间状态的情况。
- 持久性 (Durability):一旦事务提交,对数据库的修改是
永久
即使数据库崩溃、断电重启,数据也不会丢失。
2. 怎么创建 / 删除 一张表?
可以使用 DROP TABLE 来删除表,使用 CREATE TABLE 来创建表。
创建表的时候,可以通过 PRIMARY KEY 设定主键。
CREATE TABLE employees (
id INT AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
email VARCHAR(100),
salary DECIMAL(10, 2),
birthdate DATE,
PRIMARY KEY (id),
INDEX idx_name (name),
INDEX idx_birthdate (birthdate),
department VARCHAR(100),
location VARCHAR(100)
);
p.s. 如果要添加索引,CREATE INDEX idx_name ON employees(name); 跟 ALTER TABLE employees ADD KEY idx_name (name)是完全等价的。
3. 请写一个升序 / 降序的 SQL 语句?
可以使用 ORDER BY 来进行排序,默认是升序,可以使用 DESC 来指定降序。
比如要给员工表,以工资降序:
SELECT id, name, salary
FROM employees
ORDER BY salary DESC;
如果要多重排序,可以指定多个字段 (列):
SELECT id, name, salary
FROM employees
ORDER BY salary DESC, name ASC;
这样就按优先级,先按工资降序排序;如果工资相同,再按名字升序排序。
4. MySQL 出现性能差的原因有哪些?
- 可能是 SQL 查询用了全表扫描
- 没有使用索引
SELECT *
FROM employees
WHERE name = 'John';
- 用了索引,但索引列上有函数操作
SELECT *
FROM employees
WHERE YEAR(birthdate) = 1990;
- 模糊查询以通配符
%开头
SELECT *
FROM employees
WHERE name LIKE '%ohn';
p.s. 这里很有意思。 如果是LIKE 'John%',或是LIKE '_ohn',都是可以走索引的。
前者是因为索引是有序的,可以直接定位到John开头的部分;后者是因为_代表单个字符,索引定位到以ohn作为第2,3,4个字符的记录。
- 也可能是查询语句过于复杂,如多表
JOIN或嵌套子查询
- 多表
JOIN:
SELECT *
FROM employees
JOIN departments ON employees.department = departments
JOIN locations ON departments.location = locations
意思是,把 employees 表和 departments 表通过 department 字段连接起来,再把结果和 locations 表通过 location 字段连接起来,最后返回所有字段。
这样需要扫描三张表。
- 嵌套子查询:
SELECT * FROM 订单表
WHERE 用户id IN (
SELECT id FROM 用户表
WHERE 城市 IN (
SELECT 城市名 FROM 城市表
WHERE 省份 = '广东'
)
)
这样也需要扫描三张表。
- 当然也有可能单纯因为单张表的数据量过大
通常情况下,添加索引就能解决大部分性能问题。对于一些热点数据,还可以通过增加 Redis 缓存,来减轻数据库的访问压力。
5. 怎么存储emoji?
emoji 是 4 个字节的 UTF-8 字符,而 MySQL 默认的 utf8 字符集只支持 3 个字节的 UTF-8 字符,所以需要把字符集改成 utf8mb4 字符集 (m: minimum, b: bytes)。
ALTER TABLE 表名
CONVERT TO CHARACTER SET utf8mb4 -- 将字符集改为 utf8mb4
COLLATE utf8mb4_unicode_ci; -- 将排序规则改为 utf8mb4_unicode编码标准_不区分大小写(Case Insensitive)
p.s. _ci是Case Insensitive, 不区分大小写;_ai是Accent Insensitive, 不区分重音符号, 比如 é 跟 e 是一样的。
可以通过 SHOW VARIABLES WHERE Variable_name LIKE 'character\_set\_%' OR Variable_name LIKE 'collation%'; 查看。
二、数据库架构
1. MySQL 分层架构
-
连接层主要负责客户端连接的管理,包括验证用户身份、权限校验、连接管理等。可以通过数据库连接池来提升连接的处理效率。
-
服务层是 MySQL 的核心,主要负责查询解析、优化、执行等操作。在这一层,SQL 语句会经过解析、优化器优化,然后转发到存储引擎执行,并返回结果。这一层包含查询解析器、优化器、执行计划生成器、日志模块等。
-
存储引擎层负责数据的实际存储和提取。MySQL 支持多种存储引擎,如 InnoDB、MyISAM、Memory 等。
binlog 在服务层,负责记录 SQL 语句的变化。它记录了所有对数据库进行更改的操作,用于数据恢复、主从复制等。

2. 一条查询语句是如何执行的?
当我们执行一条 SELECT 语句时,MySQL 并不会直接去磁盘读取数据,而是经过 6 个步骤来解析、优化、执行,然后再返回结果。
- 客户端发送 SQL 查询语句到 MySQL 服务器
- MySQL 服务器的
连接器接收到请求,跟客户端建立连接、获取权限、管理连接- 这里可能多一步:
查询缓存。如果之前有执行过相同的 SQL 语句,并且结果还在缓存中,就直接把缓存结果返回给客户端,省去后续步骤(如上面的MySQL分层架构图,跟存储引擎无关)
- 这里可能多一步:
解析器对 SQL 语句进行解析, 检查语句是否符合 SQL 语法规范,确保数据库、表、列都是存在的;并处理 SQL 语句中的名称解析和权限验证优化器负责确定 SQL 语句的执行计划,选择最优的执行路径,比如选择使用哪些索引?决定表之间的连接顺序等执行器会调用存储引擎的 API 来进行数据的读写存储引擎负责查询数据,读取磁盘上的数据页到内存中,并把执行结果返回给客户端。客户端收到查询结果了,完成这次查询请求。
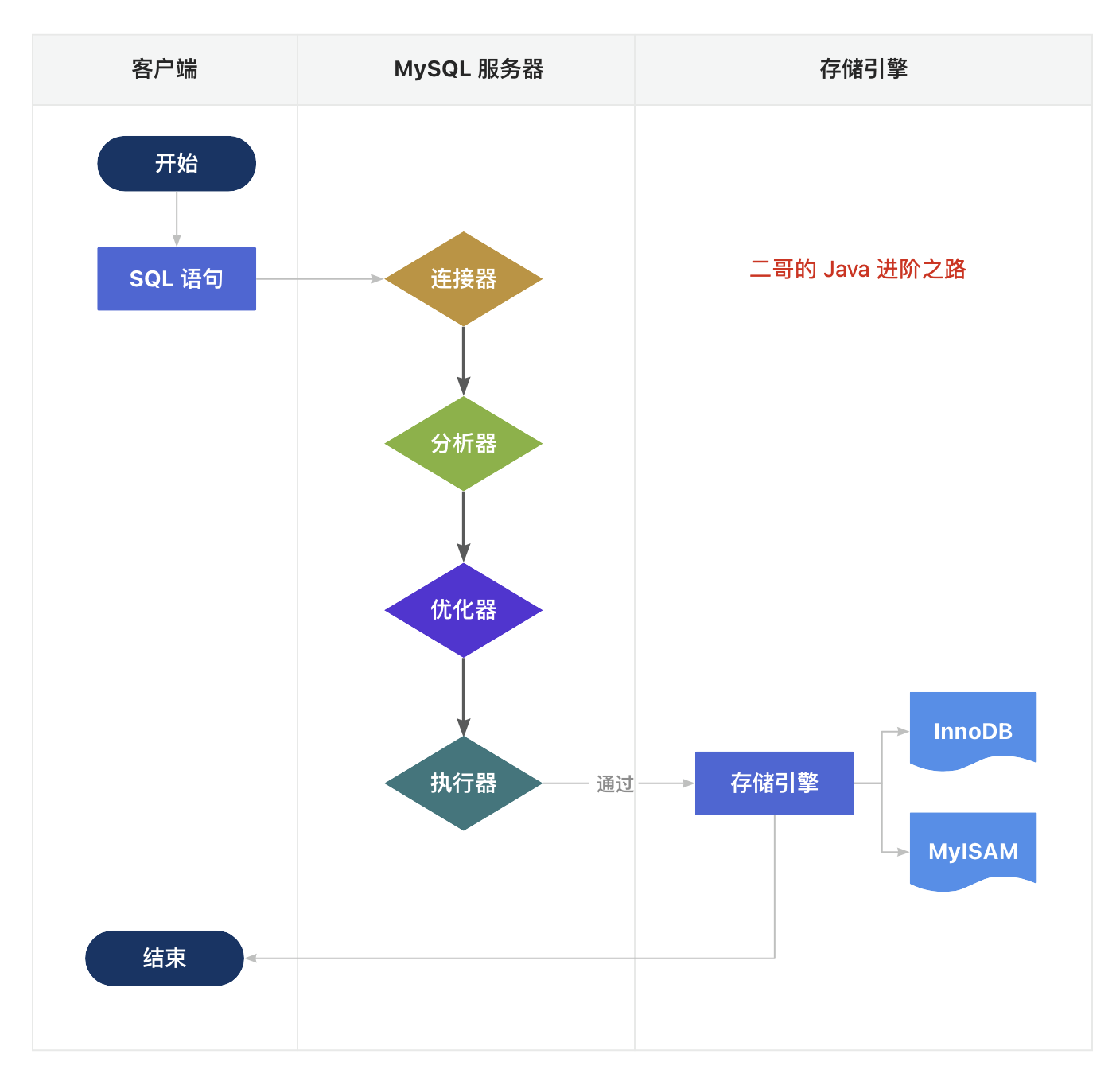
三、存储引擎
1. MySQL有哪些常见的存储引擎?
MySQL 有多种存储引擎,常见的有MyISAM、InnoDB、MEMORY等。
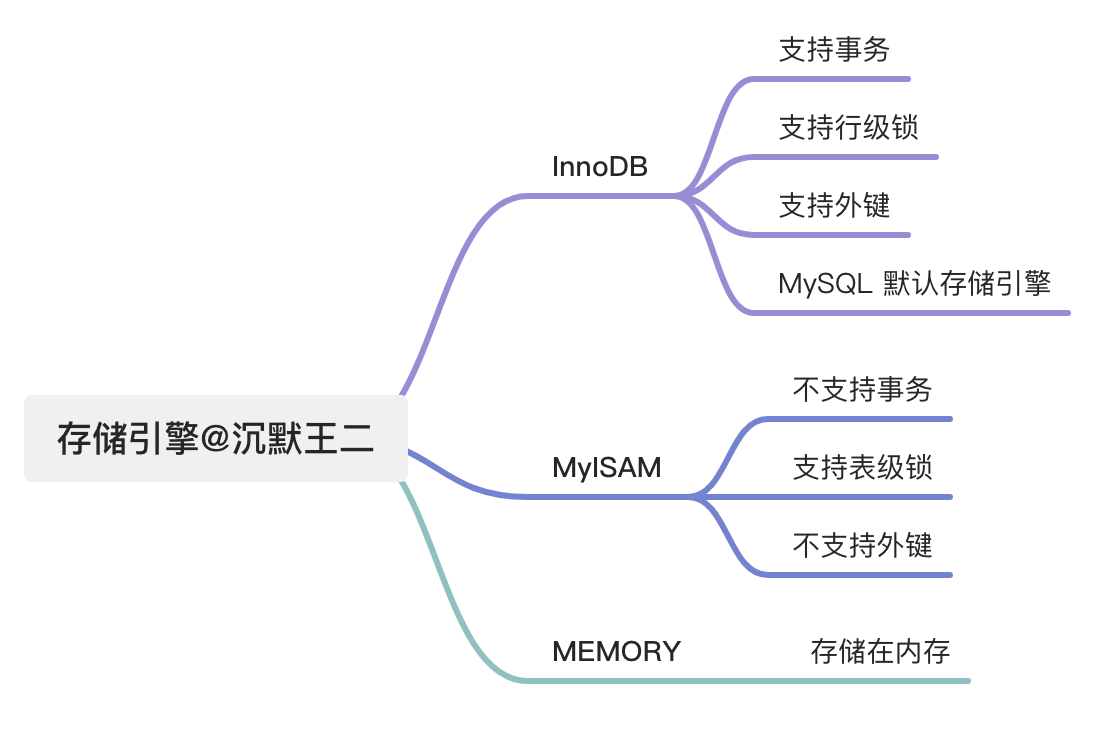
- InnoDB (现代 MySQL 的默认存储引擎)
- 支持
事务:保证数据操作的完整性 (原子性) - 支持
行级锁:多个用户同时操作时,只锁定被修改的行【提高并发性能】 - 支持
外键:可以建立表与表之间的关联关系 - MySQL 默认存储引擎
- MyISAM (旧版引擎)
- 不支持
事务 - 只支持
表级锁:当一个用户在修改表时,整个表都会被锁定,其他用户只能等待【低并发性能】 - 不支持
外键
- MEMORY (内存引擎)
- 数据存储 RAM 中,读写速度非常快
- 但:数据库重启后,数据会丢失
四、日志
1. MySQL 的日志文件有哪些?
有 6 大类:
- 错误日志 (error log) 用于问题诊断
- 慢查询日志 (slow query log) 用于 SQL 性能分析
- 一般查询日志 (general log) 用于记录所有的 SQL 语句
- 二进制日志 (binlog) 用于主从复制和数据恢复 【记录所有
修改数据库状态的 SQL 语句,以及每个语句的执行时间,如 INSERT、UPDATE、DELETE 等,但不包括 SELECT 和 SHOW 这类的操作】 - 重做日志 (redo log) 用于保证
事务持久性【记录对于 InnoDB 表的每个写操作,不是 SQL 级别的,而是物理级别的,主要用于崩溃恢复】 - 回滚日志 (undo log) 用于事务回滚和
MVCC(Multi-Version Concurrency Control, 多版本并发控制)【Undo Log 存储了数据的所有历史版本,为 MVCC 提供了时间机器,确保读操作可以获取到事务开始时的数据“快照”,从而实现非阻塞的并发读写】
1.1 重点来讲讲 binlog?
binlog ��是一种二进制日志,会在磁盘上记录数据库的所有更改操作。
如果误删了数据,可以通过 binlog 来恢复数据,回退到误删之前的状态。
# 步骤1:恢复全量备份
mysql -u root -p < full_backup.sql
# 步骤2:应用Binlog到指定时间点
mysqlbinlog --start-datetime="2025-03-13 14:00:00" --stop-datetime="2025-03-13 15:00:00" binlog.000001 | mysql -u root -p
如果要搭建主从复制,就可以让从库定时读取主库的 binlog。
MySQL提供了三种格式的binlog:
- Statement:SQL语句级别
- Row:行级别
- Mixed:混合模式(默认是row级别)
那从后缀上看,binlog文件又分为两类:
- .index:
索引文件,记录了所有 .0000xx 文件的列表 - .0000xx:
二进制日志文件,真正存储了实际的binlog记录内容的文件,被.index文件管理
binlog 默认是关闭的。生产环境中是一定要启用的,可以通过在 my.cnf 文件中配置 log_bin 参数,以启用 binlog。
log_bin= mysql-bin # 开启binlog,文件名字将为 mysql-bin.000001, mysql-bin.000002 ...
max_binlog_size= 104857600 # 设置单个binlog文件的最大字节数量为 100MB
expire_logs_days= 7 # 设置binlog文件的过期时间为7天,超过这个时间的binlog文件将被自动删除
binlog-do-db= database_name # 只记录指定数据库的更改操作到binlog中
binlog-ignore-db= database_name # 忽略指定数据库的更改操作,不记录到binlog中
sync_binlog= 1 # 每写缓冲多少次,就同步一次到磁盘,1表示每次写入都同步,提高数据安全性,但可能影响性能(默认值是0)
1.2 binlog 的配置参数都了解哪些?
如上。
1.3 都有 binlog 了,为什么还要 redo log 和 undo log?
binlog 属于 server 层,与存储引擎无关,无法直接操作物理数据页。
redo log 和 undo log 才属于 InnoDB 存储引擎层,直接操作物理数据页。
具体举例. 比如我:
UPDATE employees
SET salary = salary * 1.1
WHERE department = 'Sales';
COMMIT;
刚刚commit成功后,binlog 会记录这条 SQL 语句:
UPDATE employees SET salary = salary * 1.1 WHERE department = 'Sales';
此时,在数据页还没来得及写入磁盘前,数据库崩溃了。
- binlog 要从第一条 binlog event 开始重放,无法只恢复“一个 dirty page”
- binlog 是 server 层面、逻辑级别的日志,无法定位“哪个具体的物理数据page的哪个位置的字节”需要恢复
- binlog 重放可能会引起数据不一致:
- UPDATE 的时候可能已经修改了header了,然后crash
- 此时页面是一个结构损坏、无法解析的状态
- binlog 再来执行一次,会炸库,因为 SQL 无法解析这个损坏的页面
总得来说,我们需要:
- undo log 来 撤销未提交的事务
- redo log 来 恢复已提交,但未刷盘的事务
- binlog 来 逻辑的记录整个SQL或者行变化
执行顺序是:
事务开始/创建事务对象 -> 读入数据页到buffer pool -> 生成 undo log -> 修改数据页 -> 生成 redo log (prepare 状态) -> MySQL 写 binlog -> redo log 变为 commit 状态 (真正的提交事务) -> 后台异步将 redo log 刷盘 -> 后台异步将数据页刷盘
p.s. 我们说的数据库都是在 buffer pool (内存缓冲池) 里操作数据页的,只有后台异步刷盘的时候,才会把数据页写回磁盘。磁盘的目的只是持久化存储,平时的读写都是在内存中完成的。
p.s. 三者的具体形式如下:
-- Binlog
# SQL 语句级别
UPDATE employees SET salary = salary * 1.1 WHERE department = 'Sales';
# row 级别
table employees {
id: 101,
salary: 5500.00 -> 6050.00
}
-- Redo Log
page 0x0001 {
offset 0x0100: 5500.00 -> 6050.00
}
-- Undo Log
id: 101, salary: 6050.00 -> 5500.00
1.4 redo log 的工作机制?
当事务启动时,MySQL 会为该事务分配一个唯一标识符。
在事务执行过程中,每次对数据进行修改,MySQL 都会生成一条 Redo Log,记录修改前后的数据状态。
- 这些 Redo Log 首先会被写入内存中的
Redo Log Buffer - 当事务提交时,MySQL 会将 Redo Log Buffer 中的内容刷新到磁盘上的 Redo Log 文件中
- 只有当 Redo Log 被成功写入磁盘后,事务才被认为是提交成功的
详情可见上面的 1.3 小节中的执行顺序部分
当 MySQL 崩溃重启时,会先检查 Redo Log:
- 对于已经提交的事务,mysql 会重放 Redo Log
- 对于未�提交的事务,mysql 会通过 Undo Log 来回滚这些修改
Redo Log 通常采用循环写入的方式,当文件写满后会覆盖最早的日志记录,以节省磁盘空间。
于是为了避免覆盖掉还未应用的 Redo Log,MySQL 会定期将内存中的数据页刷新到磁盘上,这个过程称为 Checkpoint。
重启时,只需要从 Checkpoint 之后的 Redo Log 开始重放即可。
1.5 redo log 文件的大小是固定的吗?
redo log 文件是固定大小的,通常配置为一组文件,使用环形方式写入,旧的日志会在空间需要时被覆盖。

命名方式 ib_logfile0, ib_logfile1 ... ib_logfileN
默认是 2 个文件,每个 48 MB. 可以通过 innodb_log_files_in_group 参数配置文件个数;通过 innodb_log_file_size 参数配置每个文件的大小。
1.6 WAL?
WAL (Write-Ahead Logging),预写日志。
预写日志是 InnoDB 实现事务持久化的核心机制,它的思想是:先写日志再刷磁盘。即在修改数据页之前,先将修改记录写入 Redo Log。
这样的话,即使在数据页还没来得及写入磁盘前,数据库直接就崩溃了��,MySQL 也可以通过 Redo Log 来恢复数据。
2. 为什么要两阶段提交?
1.3 中已经提到,MySQL 的事务提交是分为两个阶段的:
- 读入 buffer pool
- undo
- 修改data page
- redo log (prepare)
- 写 binlog
- redo log (commit)
这样设计的目的是为了保证数据的一致性。

-
假设MySQL在预写 redo log 和写 binlog 之间崩溃了:
MySQL 重启后,发现 redo log 处于 prepare 状态,没有 commit,那么就不会应用这些 redo log;
同时 binlog 也还没有写入数据。 -
假设MySQL在写 binlog 和提交 redo log 之间崩溃了:
MySQL 重启后,发现 redo log 处于 commit 状态,那么就会应用这些 redo log, InnoDB会提交事务; 同时 binlog 也已经写入数据,所以从库也会同步到该事务的数据。
一损俱损,一荣俱荣了属于是。
2.1 XID
XID (Transaction ID),binlog 中用来标识事务提交的唯一标识符。