Homework2
| Name | ID |
|---|---|
| Yuanjun Feng | 528668 |
| Miro Ye | 527238 |
Short Answer Questions
question 1
We have Update1:
Update2:
We have
so
Let . So we have:
because . Only when , the function equals 1, and we have
Finally we get
question 2
-
The Deadly Triad is the combination of function approximation, bootstrapping, and off-policy. When these three properties are combined, learning can diverge with the value estimates becoming unbounded.Bootstrapping means targets include current estimates, and with function approximation updates can inappropriately change other states—if learning is off-policy, those bootstrap values may not be updated often enough, yielding harmful dynamics and possible divergence.
-
Instability / divergence risk from the triad: deep Q-nets + one-step bootstrapping + off-policy updates can blow up action values. Yet DQN famously combines all three, motivating careful design. Overestimation bias in max-backup targets (classic Q-learning) increases instability. Empirically, among four targets, basic Q-learning had the highest fraction of soft-divergences; target-Q and double-Q were most stable.
-
Bootstrapping on a separate target network reduces instability: the target cannot be inadvertently updated immediately, so divergence occurs less often. Empirically, target Q and double Q are the most stable among the four bootstrap targets, precisely because they use target networks; this effect is also highlighted in the Discussion.
question 3
Maximization bias arises in vanilla Q-learning because the same noisy estimator both selects the greedy action and evaluates it, so is systematically overestimated. Double Q-Learning reduces this bias by decoupling selection from evaluation: use one estimator (the online network) to pick the action and another (the target network) to score it: . Because the selection noise and the evaluation noise come from different parameters, a spurious high estimate can’t both win the max and inflate its own target, yielding much lower overestimation and more stable learning.
Deep Q-Network (DQN) Experiment Report
1. Experiment Description
This experiment systematically compares the performance of 7 different DQN variants:
- Basic DQN - Baseline implementation
- Double DQN - Reduces Q-value overestimation
- Dueling DQN - Separates state value and advantage functions
- N-Step (3-step) - Uses multi-step returns
- PER - Prioritized Experience Replay
- N-Step + PER - Combines N-Step and PER
- All-In-One - Combines all four improvements (Double + Dueling + N-Step + PER)
2. Experiment Setup
2.1 Environment Configuration
- Environment: OpenAI Gymnasium CartPole-v1
- State Space: 4-dimensional continuous state (position, velocity, angle, angular velocity)
- Action Space: 2 discrete actions (left, right)
- Reward: +1 for each time step
- Termination Condition: the pole exceeds 12 degrees or the cart moves out of the range
- Max Score: 500 points (the maximum episode length of CartPole-v1)
2.2 Training Parameters
Training Steps: 50,000
Batch Size: 128
Learning Rate: 0.002
Discount Factor (γ): 0.99
Target Network Update Frequency: every 3 steps
Epsilon Decay: from 1.0 to 0.05 (12,500 steps)
Hidden Layer Size: 64
Activation Function: ELU
3. Experiment Results
3.1 Convergence Speed Comparison
| Rank | Experiment Name | Steps to 500 | Relative to Baseline |
|---|---|---|---|
| 1 | N-Step + PER | 4,000 | 4.5x Acceleration |
| 2 | All-In-One | 6,000 | 3.0x Acceleration |
| 3 | N-Step (3-step) | 8,000 | 2.25x Acceleration |
| 4 | Double DQN | 14,000 | 1.29x Acceleration |
| 5 | Basic DQN | 18,000 | Baseline |
| 6 | Dueling DQN | 18,000 | No Improvement |
| 7 | PER | 18,000 | No Improvement |
We find that:
N-Step + PERcombination is the best (4.5x acceleration)N-Stepis the most effective single improvement (2.25x acceleration)Double DQNhas a noticeable but small improvement (1.29x acceleration)Dueling DQNandPERalone have no obvious advantage in simple tasks
Anyway, all methods eventually reached Max Score 500.0, which proves that they all can solve the CartPole task after training.
3.2 Training Curve Analysis
- The training return climbs steadily and converges to 500.
- The
TD lossshows a high initial variance that diminishes as the policy stabilizes, and N-Step has a faster convergence speed. - The
average Q-valuesincrease early and stabilize. Double DQN's Q platform is slightly lower and more stable, fitting the description of "overestimating the lower estimate".
Figures for each variant are included below.
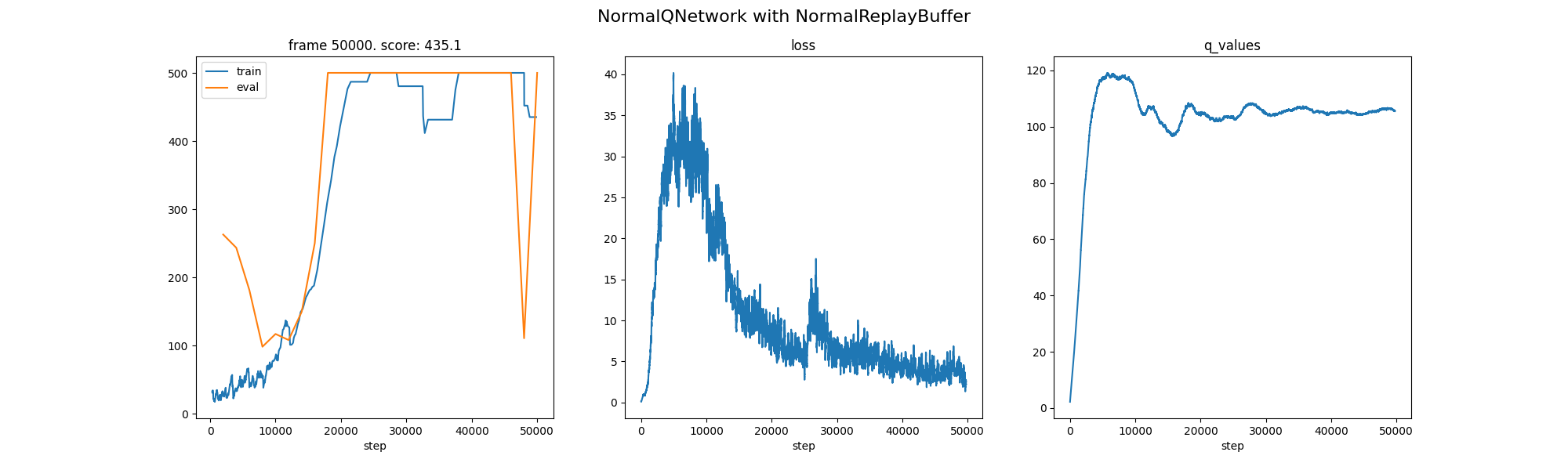 DQN: Baseline convergence within ~18k steps.
DQN: Baseline convergence within ~18k steps.
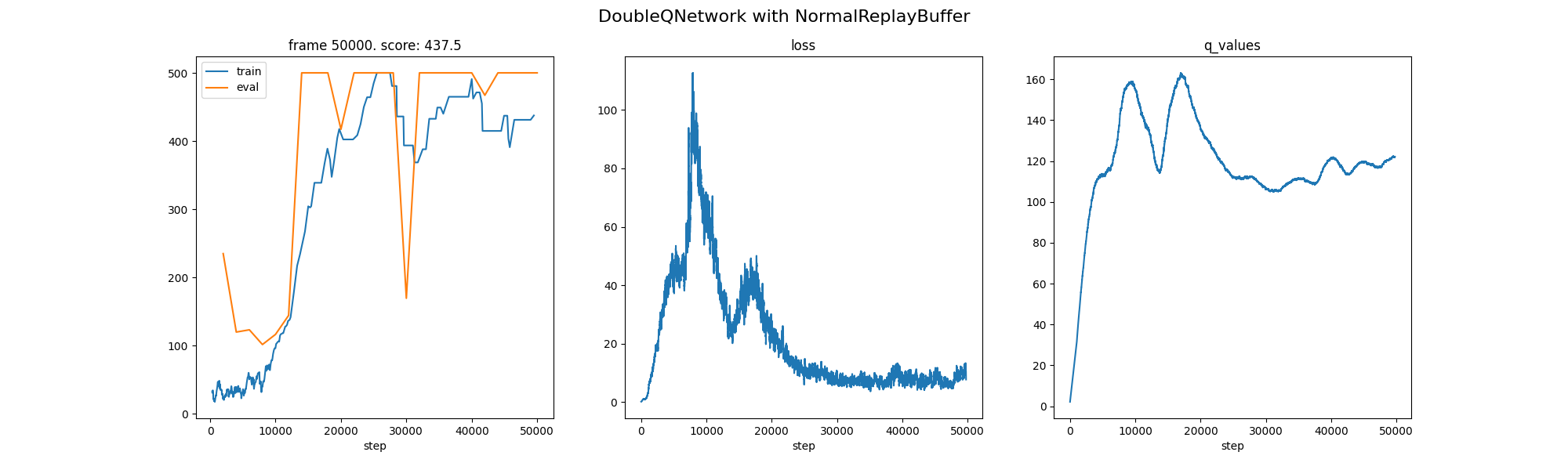 Double DQN: Reduced Q overestimation, slightly faster stabilization.
Double DQN: Reduced Q overestimation, slightly faster stabilization.
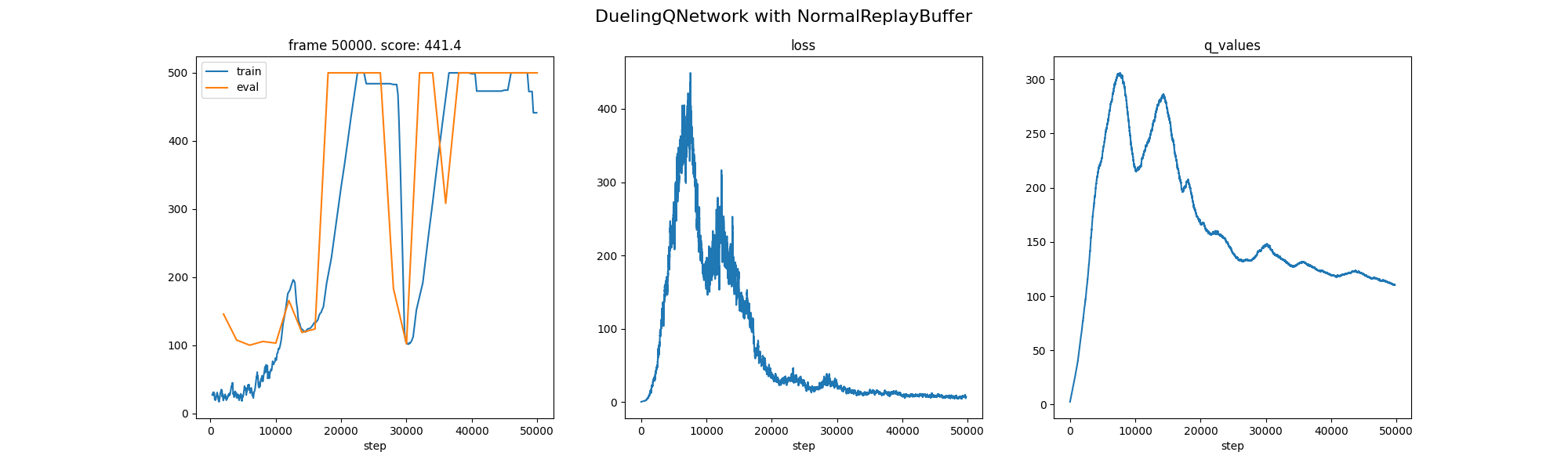 Dueling DQN: Similar on CartPole; stronger on tasks with many similar-valued actions.
Dueling DQN: Similar on CartPole; stronger on tasks with many similar-valued actions.
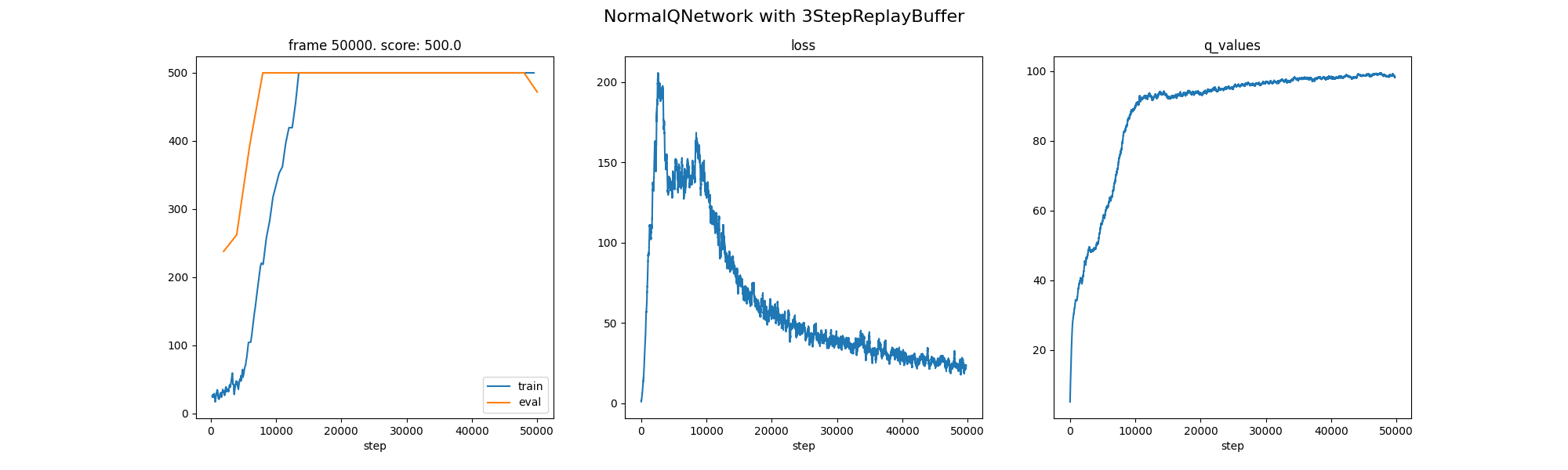 N-Step (3): Faster convergence via multi-step targets.
N-Step (3): Faster convergence via multi-step targets.
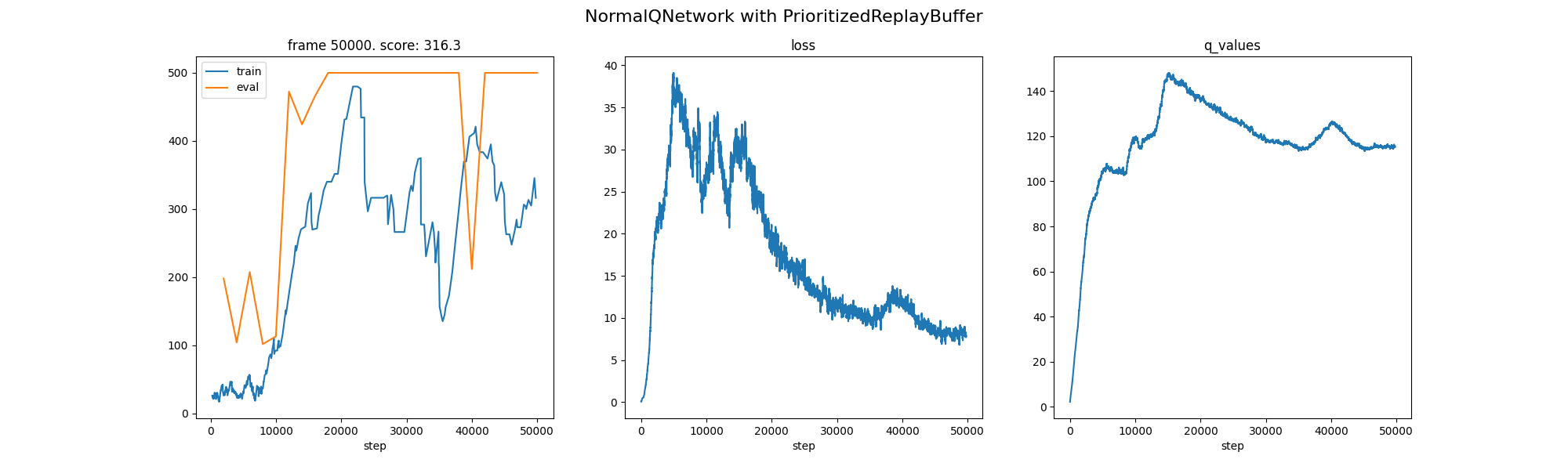 PER: Mixed effect on this simple task; helps more when dynamics are diverse.
PER: Mixed effect on this simple task; helps more when dynamics are diverse.
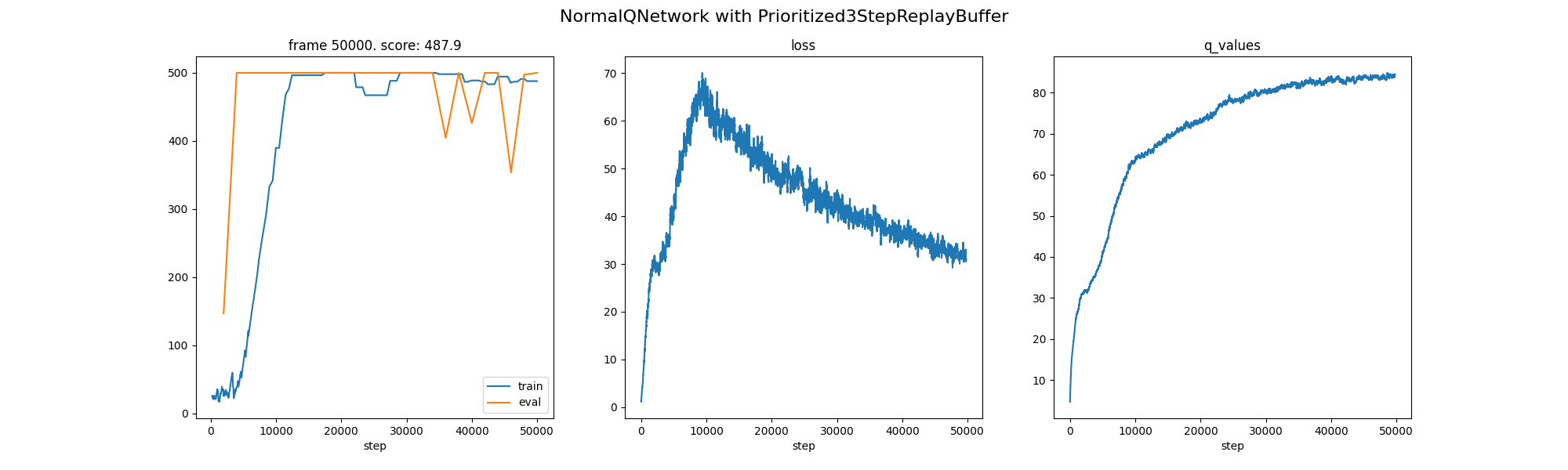 N-Step + PER: Best overall speed on this task.
N-Step + PER: Best overall speed on this task.
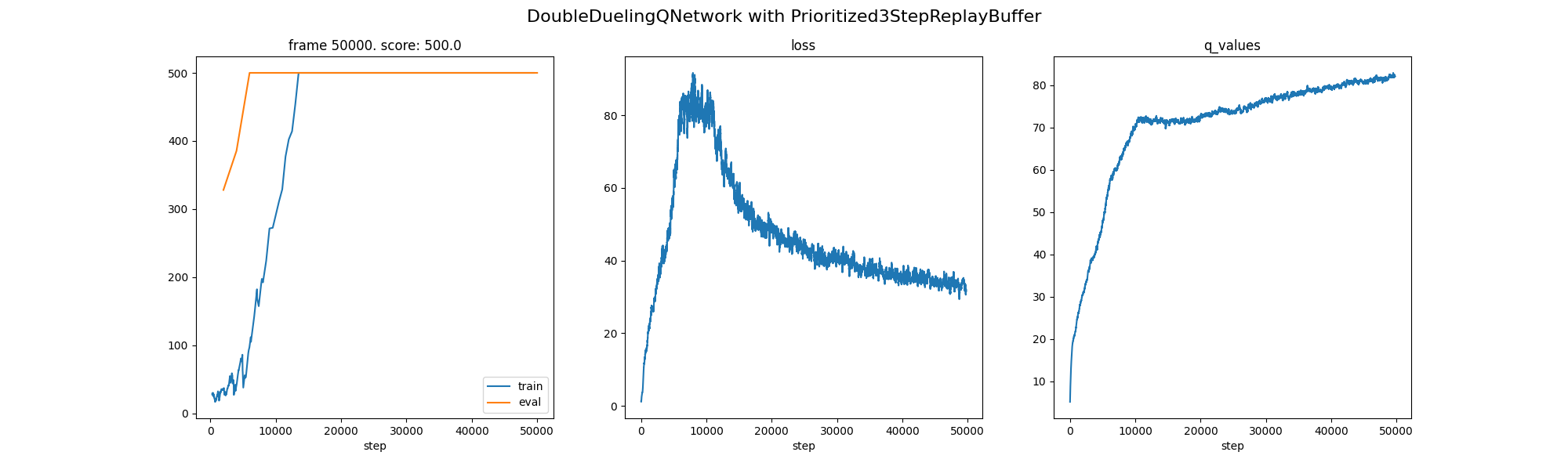 All-In-One: Strong, close to the best combo.
All-In-One: Strong, close to the best combo.
4. Method Analysis
- N-Step reduces bias in the target estimate at the expense of slightly higher variance by spreading rewards over several steps, which dramatically speeds up learning.
- PER corrects sampling bias using importance sampling weights and gives priority to informative transitions with substantial TD errors; advantages vary depending on the task.
- Double DQN reduces overestimation by separating action selection and evaluation; the effect is slight but steady.
- Dueling DQN decomposes Q into value and advantage; the benefit is minimal on CartPole.
5. Experiment Conclusion
- On CartPole, the combination of N-Step and PER converges the fastest; the benefit of using N-Step alone is also significant.
- Double DQN is slightly more stable and has lower overestimation.
- Dueling DQN has minimal benefits on this environment.
- All methods eventually reach Max Score 500, indicating successful policy learning.