MidTerm Review
Lecture 1 : Intro
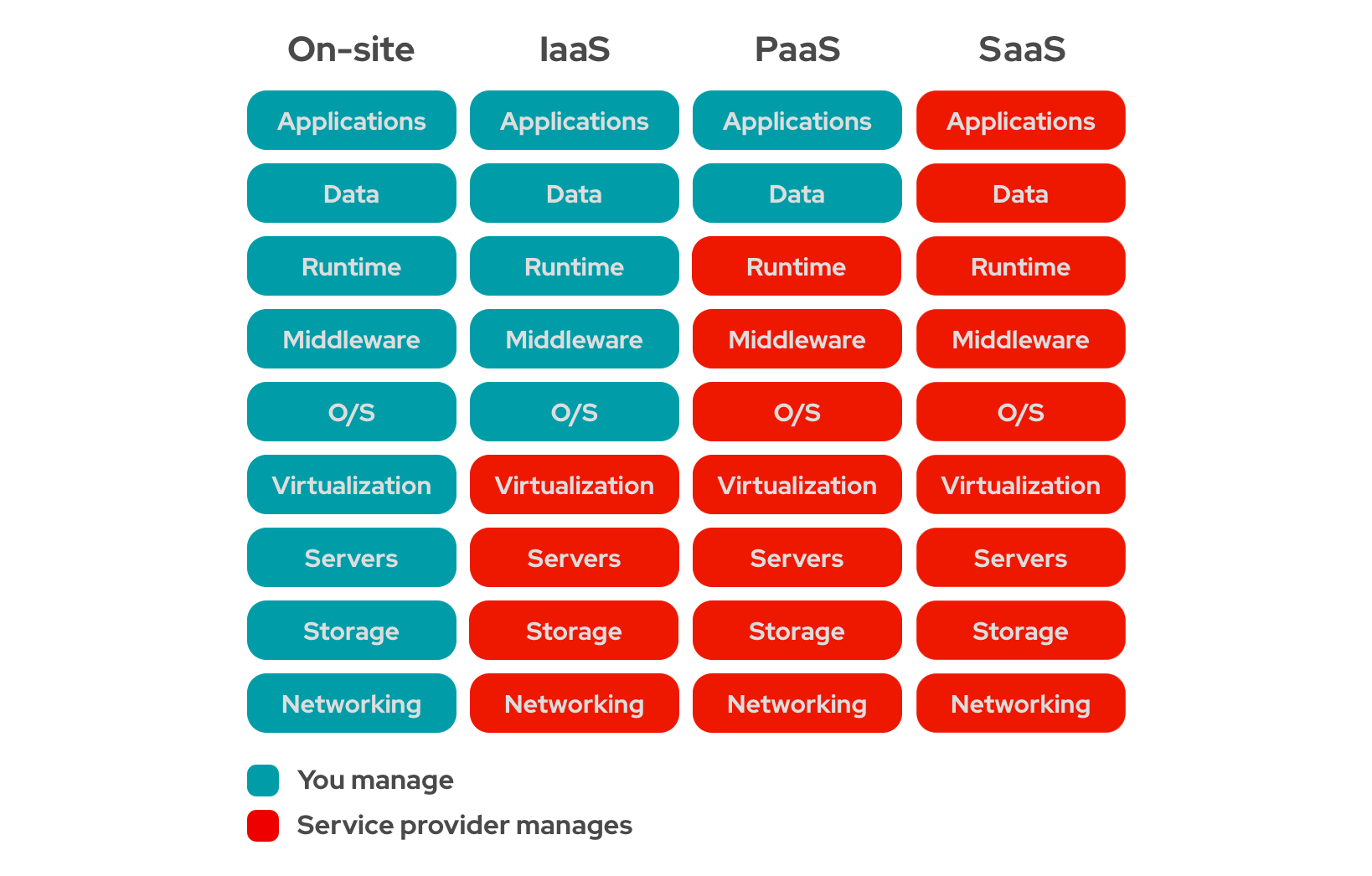
Types of Cloud Computing
-
SaaS (Software as a Service)
based on delivery of complete software applications that run on infrastructure the SaaS vendor manages.
eg. Gmail, Google Docs -
PaaS (Platform as a Service)
based on delivery of platforms and infrastructure services that enable developers to build and deploy applications. but they should provide their own code to be deployed.
eg. AWS S3, Heroku -
IaaS (Infrastructure as a Service)
based on delivery of only infrastructure services. users should handle all the software and hardware resources, including operating system, managing software and deployment. eg. AWS, Google Cloud Compute Engine
Benefits of Using Cloud Computing versus Building Your Own?
- Cloud?

More Definitions
- Hybrid Cloud: Public 和 Private 的混合使用. - 兼顾成本和安全(Confidentiality / Security)
- Multi-Cloud:
使用多个云服务提供商. - 避免
Ventor Lock-in - Severless Computing:
不是没有服务器,是不用管理服务器. 按
执行次数计费。 - 节省成本和时间 eg. AWS Lambda, Azure Functions
还有个概念叫边缘计算(Edge Computing),它是介于云计算和物联网之间的计算模式。它将计算资源部署在离数据源更近的地方,以减少延迟和提高效率 (Reduce latency, improve bandwidth efficiency, and enables real-time processing)。
Containers (Docker) & Orchestration (Kubernetes, K8s)
-
容器:
- 以
Docker为代表,是一种standard way to package and deployapplication. - 将整个
application及其依赖打包进一个single unit, 可以轻松地保证在不同的环境中运行的reliability。
- 以
-
编排:
- 就专讲
Kubernetes. 是一种open-source container orchestration platform,最早由Google开发 - 用于管理
containers的部署、伸缩和调度 (manage containerized applications at scale in cloud environments). - 自动化部署、扩展和管理这些容器 (Automates the deployment, scaling, and management of containerized workloads).
- 就专讲
Lab 1
-
API: Application Programming Interface
- 一套让不同系统相互通信的规则和端点 (
endpoints). - API可以用来执行
CRUD操作 (Create, Read, Update, Delete).
- 一套让不同系统相互通信的规则和端点 (
-
FastAPI: Python的web框架,用于构建API.
from fastapi import FastAPI, Request
from fastapi.templating import Jinja2Templates
import json
# FastAPI 实例创建
app = FastAPI()
# Jinja2Templates: 用于渲染HTML的模板
templates = Jinja2Templates(directory="templates")
# FastAPI的endpoint / 路由
@app.get("/")
# 需要渲染到HTML的时候就需要有request参数
def read_root(request: Request):
# templates.TemplateResponse: 模板响应
return templates.TemplateResponse(
"index.html",
{
"request": request,
"message": " Hello World from FastAPI!",
"users": get_users_data(),
},
)
# 辅助函数 - 读取users.json文件
def get_users_data():
with open("users.json", "r", encoding="utf-8") as file:
file_contents = "".join(file.readlines())
data = json.loads(file_contents)
return data
# 第二个路由,依旧request
@app.get("/users")
def get_users(request: Request):
with open("users.json", "r", encoding="utf-8") as file:
file_contents = "".join(file.readlines())
data = json.loads(file_contents)
return templates.TemplateResponse(
"users.html",
{
"request": request,
"users": data["users"],
},
)
# 第三个路由,依旧request
@app.get("/movies")
def read_movies(request: Request):
with open("movie_data.json", "r", encoding="utf-8") as file:
file_contents = "".join(file.readlines())
data = json.loads(file_contents)
return templates.TemplateResponse(
"movies.html",
{
"request": request,
"movies": data["results"],
},
)
Lecture 2 : Cloud Storage, APIs, and Access Controls
Cloud Storage
- hardware storage 的短板:
- expensive
- inflexible
- difficult to scale
所以我们 Big 3 云服务商都各自有solution:
- AWS S3
- Azure Blob Storage
- Google Cloud Storage
Cloud Storage的优点:

S3 Bucket
这学期就只学 Amazon S3.
S3 stands for Simple Storage Service - 三个S. (p.s. EC2 stands for Elastic Cloud Compute - 2个E.)
S3 stores files as objects. 它有很多用途:
- Data Storage
- Backup & Recovery
- Hosting Static Websites
- Data Archiving
S3 跟传统的文件系统(如C盘)有最重要的区别:
- 文件系统是树状层级结构 (tree hierarchy)
- S3 是基于键的存储. 有三个核心概念:
- 存储桶 (Bucket): 最外层文件夹
- 对象 (Object): file. 每一个file就是一个object, 每一个object都有
- 键 (Key): 这个object的唯一标识符-路径. 形如
bucket_name/object_name.
由于S3 Bucket的名字是Global NameSpace的,所以一个bucket的名字要全AWS、全世界唯一..
RBAC: Role-Based Access Control
如果我们对S3 Bucket不加任何访问控制,那么任何人都可以访问这个bucket里的所有object,有安全隐患。
RBAC的解决方案是,我们不给individual user直接访问S3 Bucket的权限.
而是group users by roles, 给不同的role分配不同的权限。
优点是:
- Enhanced Security: 只有被授权的user才能访问S3 Bucket.
- Simplified Management: 只需要管理role的权限,不需要管理每个user的权限。
- Increased Efficiency
- Improved Compliance: 符合合规性要求。
PLP: Principle Of Least Privilege
- RBAC 的
Principle Of Least Privilege (PLP): 只授予用户完成其工作所需的最低权限,而不是授予更多权限。- Enhanced Security: Minimizes the blast radius of potential attacks or accidental data breaches. 最小化 潜在攻击 / 意外数据泄露 的影响半径
- Reduced Errors: 减少误操作(别的用户没法再误改误删)
- Improved Compliance
我们通过IAM (Identity and Access Management)来实现PLP.
PLP?- Start with least privilege
- Begin by granting minimal permissions
- Regularly review permissions
- Use temporary credentials
- Provide short-lived access for specific tasks using IAM roles and STS (Security Token Service)
- Monitor activity
- Use
AWS CloudTrailto track user actions and resources access.
- Use
比如给你的EC2 instance分配一个IAM role去访问S3 Bucket, 这个role只有读取S3 Bucket的权限,没有完全访问权限。
IAM: Identity and Access Management
IAM服务的几个核心Components:
- Policy: 这是一个JSON文件,定义了哪些用户/角色/组的权限可以操作哪些资源。
- Permission: 这是具体操作,比如
s3:CreateBucket,s3:StopInstance等。 - Role: 这是一个身份,附加了一堆
Policies。Role可以被用户使用,也可以被如EC2 instance使用。 - User: 人,有用户名密码(登录),或API Key (代码访问AWS)。
- Instance Profile: 这就是
3中提到的,把Role附加到EC2 instance上的机制。(最安全给我们的云应用,如EC2上的FastAPI,授权的方式)
IAM Authentication?
- 从AWS外部:
- 从IAM Dashboard生成Root User的API Credentials (Access Key ID & Secret Access Key)
- 下载个AWS CLI,配置好credentials
- Boto3 和 CLI 就会自动获取credentials,然后就可以操作AWS了。
- !! 最不安全
- 从AWS内部:
- Attach 一个 IAM Role to an EC2 instance
- Boto3 和 CLI 就会自动获取Role的credentials,然后就可以操作AWS了。
- 搞个EC2
- 在EC2上“修改IAM Role”,Create a new IAM Role
- 用例选EC2, 权限选
S3 -> AmazonS3FullAccess(一般实际会选AmazonS3ReadOnlyAccess) - 给role起个名
这样EC2 instance 和 S3 Bucket的权限,就通过IAM Role关联起来了。
然后就可以:
- 本机SSH EC2 instance
aws s3 cp s3://my-bucket/my-file.txt .这样就把S3 Bucket里的文件下载到EC2 instance的当前目录了。
Boto3: Python SDK for AWS
Boto3 是 AWS 官方的 Python SDK (Software Development Kit).
- Provides a consistent API for all AWS services.
- Supports both
low-levelandhigh-levelabstractions.
最主要的目的就是Automation, for no human in the loop.
他还有其他优势,诸如:

有一些key concepts需要做解释:
- Resources(资源): 高阶的(high-level) abstraction,比如
s3.Bucket.. - Clients(客户端): 低级的(low-level) access to AWS services APIs, 比如
s3_client.list_buckets() - Sessions(会话): 用于管理AWS credentials和configuration settings.
- Waiters(等待者): 很重要的概念!! 有些操作(如创建一个数据库)并不是立即完成的。Waiter会自动等待这个操作完成,再去执行脚本的下一步,而不是让我们写一个for loop去死等。
- Paginators(分页器): 有些操作(如获取一个S3 Bucket里的所有object)可能返回很多结果。Paginator会
自动分页(如一次加载十条),而不是让它们一次性全部加载到内存里。
Boto3 Code
import boto3
s3 = boto3.resource('s3')
for bucket in s3.buckets.all():
print(bucket.name)
'''
EC2也可以
'''
ec2 = boto3.resource('ec2')
instance = ec2.create_instance(
ImageId='ami-0c55b159cbfafe1f0',
InstanceType='t2.micro',
MinCount=1,
MaxCount=1,
)
'''
或者用Boto3 Client来创建一个S3 Bucket
'''
s3 = boto3.client('s3')
s3.create_bucket(Bucket='my-bucket')
s3.upload_file('my-file.json', 'my-bucket', 'my-file.json')
提前解释:
下面代码中的s3.Object('my-bucket', 'my-file.json'),是获取一个S3 Object。
第一个参数是bucket, 第二个参数则是object的key(即路径). 第一节课中提到的基于键的存储就是这个意思。
import boto3
import json
s3 = boto3.resource('s3')
def load_data():
obj = s3.Object('my-bucket', 'my-file.json')
body = obj.get()['Body'].read()
data = json.loads(body)
return data
print(load_data())
Lab 2 : Integration with AWS
lab2比起lab1的区别就在于,是通过boto3从s3 bucket加载数据,而不是从本地文件加载数据。
from fastapi import FastAPI, Request
from fastapi.templating import Jinja2Templates
import json
import boto3
# FastAPI 实例创建
app = FastAPI()
# Jinja2Templates: 用于渲染HTML的模板
templates = Jinja2Templates(directory="templates")
# boto3 访问 s3 bucket
s3 = boto3.resource('s3')
# FastAPI的endpoint / 路由
@app.get("/")
# 需要渲染到HTML的时候就需要有request参数
def read_root(request: Request):
# templates.TemplateResponse: 模板响应
return templates.TemplateResponse(
"index.html",
{
"request": request,
"message": " Hello World from FastAPI!",
"users": load_data('lab2/users.json'),
},
)
# # 辅助函数 - 读取users.json文件
# def get_users_data():
# with open("users.json", "r", encoding="utf-8") as file:
# file_contents = "".join(file.readlines())
# data = json.loads(file_contents)
# return data
# 换成:辅助函数 - 从s3 bucket读取users.json / movie_data.json文件
def load_data(key: str):
obj = s3.Object('cse427-yf', key)
body = obj.get()['Body'].read()
data = json.loads(body)
return data
# 第二个路由,依旧request
@app.get("/users")
def get_users(request: Request):
return templates.TemplateResponse(
"users.html",
{
"request": request,
"users": load_data('lab2/users.json')["users"],
},
)
# 第三个路由,依旧request
@app.get("/movies")
def read_movies(request: Request):
return templates.TemplateResponse(
"movies.html",
{
"request": request,
"movies": load_data('lab2/movie_data.json')["results"],
},
)
Lecture 3 : VM & Docker Containers
Why VM & Containers?
- 云的基石:Foundation of cloud and big data architecture.
- 行业标准:Containers are the current standard for deploying the web apps and cloud computing
- 抽象层的需求:随着apps 和 data 越来越多,我们需要一个
abstraction layerto manage them.- Application Compatibility: 我们需要
Software Isolationto focus on just my app, not the underlying infrastructure. - Distributed Computing: 当我们需要
scale up的时候,我们需要一种简单、标准化的方式来快速部署、复制和启动我们的app
- Application Compatibility: 我们需要
What is a Virtual Machine?
Virtual Machine (VM) is a software emulation of a physical computer.
它解决的问题就是Application Compatibility,让我们可以在一个Host硬件上运行多个Guest OS.
P.S. 这是一种Hardware-level abstraction.
VM通过一个叫Hypervisor(虚拟机监视器)的软件,提供操作系统隔离(OS isolation)的假象
Hypervisor 会 manage the allocation of shared and replicated resources between host & guest OS,也就是分配真实的硬件资源,比如 CPU 和 RAM,一个服务器分割成多个虚拟机,每个有自己的CPU和RAM.
- 当我们在lab2启动了一个EC2 instance的时候,实际上就是启动了一个VM.
Hypervisor 的类型:
- Type 1 : Bare Metal Hypervisor (直接在硬件上模拟硬件)
- 取代 host OS,
直接运行在物理硬件上 - 性能非常好,接近裸金属(Bare Metal)
- 目前所有的云服务商用的都是Type 1 Hypervisor!!
- 取代 host OS,
- Type 2 : Hosted Hypervisor (用软件模拟硬件)
- 应用软件类型,运行在 host OS 上,如 VirtualBox, VMware
- 性能不如Type 1,但更易于管理,适用于个人用户
VM 的问题
- Resource Overhead: Hypervisors provisions excess resource. Hypervisor分配的资源是固定的,所以总会多分,分配完就被占用了导致浪费。
- LARGE: 由于 includeing the OS kernel, 一个 VM image 就得有好几个 GB
- Slow to Boot :启动一个 VM 就跟启动一个新电脑一样慢。
这些毛病引出来一个烧烤:
我只是想运行两个独立的 web app, 真的有必要给他们各自启动一个完整的 linux 系统吗?
于是引出解决方案:
不在“硬件层”做 Virtualization, 而是在“操作系统层”进行 Isolation, 这就是Containerization。
Container
- Container 提供了与 VM 类似的
isolated environment, independent from the host OS. - Key Difference: Container 在操作系统层面上进行隔离,而不是硬件层面上。
- Containers share the underlying kernel of the host OS, but have their own isolated user space.
可以想象 Container 就像是一个轻量级的 VM (但它共享了 Host OS 的 kernel, 又有自己的空间).
- VMs implement
hardware level virtualization, while Containers implementOS level virtualization. - VMs 的 resource allocation 是
fixedby the Hypervisor, 而 Containershave no limits by default.- 这使得 Containers are
more efficientthan VMs for most apps.
- 这使得 Containers are
Container 的实现原理 - Namespace
Container 是如何实现上述的 “sharing the underlying kernel of the host OS, while owning their own isolated user space” 的?
答案是,利用了 Linux kernel feature: namespace.
Namespace 是 Container main building block 之一.
Namespace abstracts global resources (PID, network, IPC, etc.), to make them appear to the processes within the namespace as isolated instances of those resources.
Namespace将全局资源(如PID, network, IPC等)抽象为隔离的实例,使得在namespace内的进程看起来就像自己独占了这些资源一样。
Linux 提供了多种 Namespace:
- PID: 在 Container 中,你的app看到的pid可能是1,但他在host OS中可能是3456
- net: container可以有自己的
独立IP和port - mount: 挂载点(文件系统)
- IPC: 进程间通信
- uts: hostname
- user: users & UIDs (可以
sudoinside the container but not outside)
总的来说,Namespaces 让 Container 里面的 process 产生了 “i am running in an isolated os” 的假象,实际上他们都仍在“share the underlying kernel of the host OS”
P.S. 我们使用 unshare 命令来创建一个 Namespace, 例如:
unshare -n bash
当我sudo unshare --pid --fork --mount-proc bash, 这里面是没有��加上--uts这个参数的时候, 这个时候我用hostname command 会输出什么结果?
答案是:依旧会输出 host OS 的 hostname.
所以说,所以每一个global resource都是独立的。
给某一个 resource, 比如 PID, 用 unshare 创建一个 namespace, 这个namespace里面的 process 看到的这个resource (PID) 就是隔离的;但这个 process 看到的其他 resource (如 network, IPC, etc.) 依旧是共享的, host os 上的。
VM vs Container 再总结
- Container more
efficient and lightweightthan VM. - Container's resource allocation is
dynamicby the Container Runtime, while VM's resource allocation isfixedby the Hypervisor. - Container is visualized in the
OS level, while VM is visualized in thehardware level.
但:
- VM provides
full isolationfrom the host OS, while Container providespartial isolation, meaning VM ismore securethan Container. - Container
cannot run all OSas it shares kernel, while VMcanrun any OS. - GUI dev is
difficultin Container, while it'seasyin software such as VirtualBox.
所以我们说,most modern companies combine both, for security and efficiency.
Docker
Docker is a software that utilizes these kernel features to package software into lightweight containers.
它提供了一个 easy API that abstracts low-level OS visualization (底层虚拟化技术,指的就是前面讲的container的os层虚拟化,被他封装成了一个 easy API).
那么要理解Docker,我们首先需要理解Image Layer和Container Layer的区别.
首先,什么是image?
- 镜像image 是一个
read-only的 template,或者说是一个immutable的 package. - 包含了一个应用所需要的所有
一切:code, libraries, dependencies, executable files, etc.
Docker Image Layers
Docker Image 是如何构建的?答案是 分层(layers)
- 一个 image 是由多个 read-only layers 组成的
- 每个 layer 都 depends on the one before it
- images build by executing each layer
sequentially, 然后最后combing them into a single image- 比如,底层是bootfs, 然后是Debian,再上Emacs,最后是Apache..
这是 Image Layers,那在这里面什么是 Container Layer?
当我们 run a container based on an image, 我们实际上是在创建一个 writable layer on top of the image.
这个 app 就运行在这个 writable layer 上,他的所有改动都只会在最上面这个 writable layer 上.
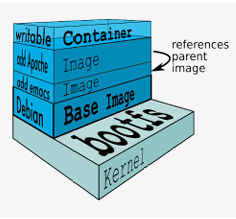
Docker Image Layers vs Docker Container Layer (KEY!!)
一般从 Docker Hub 拉取一个 Parent Image,比如 python:3 或者 alpine(一种lightweight linux distribution) 作为构建镜像的开始。

Dockerfile
创建镜像我们主要使用 Dockerfile.
- Dockerfile 是一个纯文本 text file, which contains a series of instructions for building a Docker image.
- 每个 instruction is a command that will
create a new layerin the image.
FROM <image>:<tag>: 设置父镜像。这个是 Dockerfile 的第一条指令,必须有,比如FROM python:3或者FROM alpine.- 当然如果不想依赖任何父镜像,想从零构建,可以
FROM scratch.
- 当然如果不想依赖任何父镜像,想从零构建,可以
COPY <local path> <container path>: 将本地文件复制到镜像中。RUN <command>: 执行命令。通常用来在构建时安装依赖,比如RUN pip install -r requirements.txt.CMD ["cmd"]: 设置容器启动时默认执行的命令。比如CMD ["uvicorn", "main:app", "--reload"].
Docker API (CLI)
要使用 Docker, 首先需要启动 “Docker守护进程 (Docker Daemon)”. 在 Mac / Windows 上,就是启动个 Docker Desktop 就完事了。
这个Daemon会在后台运行,监听命令。我们在CLI中敲的docker command 实际上就是和这个Daemon交互,发给他去执行。
docker build -t <image name> .: 构建镜像。-t是 tag, 用来给镜像命名。.是 Dockerfile 在当前目录下的意思。docker run <image name>: 运行容器。docker ps: 查看正在运行的容器。docker exec -it <container id> /bin/bash: 进入容器。BEST FRIEND FOR DEBUGGING!! 他允许我在一个正在运行的container里面打开一个bash shell执行命令.
docker run -p 8000:8000 my-app:demo1 做了端口转发,把container的8000端口映射到host的8000端口。
docker run -p 8001:8000 my-app:demo1 的 container log 显示的还是 8000 端口,因为在 container 内部自己的 Namespace 里面,它总以为自己运行在 8000 端口.
Store & Share Images - Docker Hub
我们 docker build 出来一个 image 了,但它现在只在我本机,如何分享? - Docker Hub
几个相关命令:
docker pull <image name>: 从 Docker Hub 拉取 image.docker tag <local-image> <dockerhub username>/<image name>:<tag>: 给 image 打 tag. (必须得有一个local image 才能打 tag)docker login: 登录 Docker Hub.docker push <dockerhub username>/<image name>:<tag>: 推送到 Docker Hub.
Multi-Platform - Docker Buildx
本机 Mac 是 ARM 架构的,但 EC2 实例是 AMD x86 架构的。那我 docker build 出来的 image 显然不能在 EC2 实例上运行。为了不给每个平台都构建推送一个不同 tag 的 image,我们使用 Docker Buildx 来解决这个问题。
Docker Buildx 是一个 CLI plugin, 它支持多平台构建 (Multi-Platform Build):
docker buildx build --platform linux/amd64,linux/arm64 -t [dockerhub username]/[image name]:[tag] . --push: 构建并推送 amd64 和 arm64 两个平台的 image 到 Docker Hub.
Buildx 引入了 Context 和 Builder 的概念。
- Context 是构建的上下文.
docker context use <context name>可以切换我们的 docker 命令应该发送给哪个 daemon ! - Builder 是 buildx 创建的一个
build instance, 它控制 docker image 如何被创建。- 所以当我们docker buildx build的时候,实际上是在使用一个 Builder 来构建 image. - 这就导致,如果我们使用--platform参数改变了平台之后;如果再需要使用默认的docker build命令 (也就是原本的单平台构建),就需要docker buildx build -t myapp --load .
Lab 3 : Docker
from fastapi import FastAPI, Request
from fastapi.templating import Jinja2Templates
import json
import boto3
app = FastAPI()
templates = Jinja2Templates(directory="templates")
# s3 = boto3.resource("s3")
'''
switch to user "Environment Variables" to access S3
'''
import os
access_key = os.getenv("AWS_ACCESS_KEY_ID")
secret_key = os.getenv("AWS_SECRET_ACCESS_KEY")
s3 = boto3.resource(
"s3",
aws_access_key_id=access_key,
aws_secret_access_key=secret_key,
)
# 剩下都不变...
lab3 的重点在于 docker 的 build 和 push,代码的改变部分只有 s3 bucket 访问。
由于 lab2 是从 一个 带着 [有 s3 bucket 访问权限的 IAM User] 的 EC2 实例 启动;lab3 的代码则是在 docker container 里面运行的,所以需要将 [有 s3 bucket 访问权限的 IAM User] 的 Access Key ID 和 Secret Access Key 设置为 Environment Variables,供代码访问 S3 bucket。
Lecture 4 : Kubernetes
Docker 漏讲重点
-
Docker 本身是不包含 linux kernel 的,它只包含 user space 的 filesystem (mount), library 以及 application code. 我们之前也强调过:Container 和 VM 的一个区别就在于,Container是共享 host OS 的 kernel,而 VM 是隔离了个Guest OS出来但也好歹有个自己的 kernel。
-
Docker 的那些 image layers / container layer 只是关于
文件系统的,跟 namespace 这种 kernel feature 无关。事实上从上面的第1条我们也知道,docker 或是任何 container runtime 都是不包含 kernel 的,他们只是利用了 linux kernel 的 namespace feature 来实现 container 的 isolation。
2条,在docker run <image name> 的那一刻- Docker 向 Host OS Kernel 请求了一个
新的process,并且给这个 process 分配了一套新的、隔离的 namespaces (PID, network, uts, mount, etc.),其中就包含了mount - Docker 开始准备
文件系统- 找到我们指定的 image 所对应的所有
read-only image layers - 在这些 image layers 之上,创建一个
writable container layer
- 找到我们指定的 image 所对应的所有
- 最后,Docker 把这些全部 layers 统一起来成一个完整的 filesystem,把这个文件系统给
挂载(mount)到这个 process 的 新的那个mount namespace里面
所以总的来说:
- namespace 是 isolation 机制本身
- layers 只是被隔离的内容之一,具体来说,就是 mount.
Why Kubernetes?
数据量太大,单个 server 无法存储 / 处理,只好分布式。
但分布式引发了新问题:
- 如何让这些机器
Highly Available? - 如何实现
容错(Fault Tolerance)? - 如何管理服务间
Communication,Data Sharing&Computation?
Kubernetes 就是来解决这些问题的编排(Orchestration)工具
Monolithic vs Microservices (单体 vs 微服务)
在讨论 K8s 如何管理服务之前,我们需要了解两种主要的软件架构风格。
- Monolithic: 整个应用被打包成一个 single executable file / deployment unit.
- 任何改动都需要重新build & deploy整个应用。
- Microservices: 整个应用被拆分成多个小的、独立的服务,各服务之间通过轻量级API(通常是HTTP/RESTful API)进行通信,
松散耦合(Loosely Coupled)。- 每个服务可以独立部署、扩展、更新。


Microservices Orchestration
当我们开始运行多个container, 比如一个web app container 和一个 database container, 我们如何管理他们?
对于单机器的简单场景,Docker Compose 可以满足我们的需求。
- 使用一个
YAML文件定义和运行多个container。 - 可以管理container之间的依赖关系,网络通信和环境变量等。
用一个.yml file加上一个docker-compose up -d就可以启动多个container.
但局限性也很大:
- 不支持remote deployment
- 不支持autoscaling
- 不支持cross-environment running containers
- 所有container都运行在同一个机器上,无法实现
Highly Available
所以真正要Highly Available、Distributed、Scalable的场景,我们需要一个更强大的工具:Kubernetes。
Kubernetes
K8s is a container orchestration platform that manages containerized applications across multiple machines, and abstracts the underlying hardware resources.
提供了:
- Highly Availability
- Scalability
- Fault Tolerance (Disaster Recovery)
- State Management
Kubernetes Key Concepts
- Node:一个 physical or virtual machine that can run a container (就是server).
- 一个 K8s Cluster 由多个 Node 组成。
- Kubelet: 运行在
每个Node上的agent.- 负责确保
Pod运行在 该 Node 上运行,并且与Control Plane通信。
- 负责确保
- Pod: 一个 K8s 的
最小 deployment unit of computation(最小可部署的计算单元).- 一个 Pod 包含 一个 Docker Container.
- 每个 Pod 都有自己的 IP address, 所以他们可以相互通信。
- Pod 是
ephemeral (短暂的), 所以他们可以被随时销毁并被新的 Pod 替代。
Kubernetes Architecture
两部分:
- Control Plane:
- 以前叫Master Node, 现在叫Control Plane.
- 至少需要一个!!!
- Cluster 的
大脑,负责调度和管理 Pod.
- Worker Nodes:
- 就是普通的Node,可以有很多个
- 负责实际运行 Pod.
Cluster 层面:
一个 K8s Cluster 由至少一个大脑也就是 Control Plane 和多个 Worker Nodes 组成。
Node 层面:
每个 Node 上运行着一个 Kubelet, 负责确保 Pod 运行在 该 Node 上运行,并且与 Control Plane 通信。
当然,一个 Node 上可以运行多个 Pod.
Pod 层面:
Pod 是 K8s 的最小 deployment unit of computation, 通常包含一个 Docker Container (当然也可以包含多个,但一般是1on1).
Control Plane 内部包含几个关键组件:
- API Server:
- 与 K8s Cluster 交互的
唯一入口.
- 与 K8s Cluster 交互的
- etcd:
- 一个 Highly Available 的 Key-Value Storage Database. 保存了整个 Cluster 的 Configuration &
状态(State).
- 一个 Highly Available 的 Key-Value Storage Database. 保存了整个 Cluster 的 Configuration &
- Scheduler:
- 负责调度 Pod 到合适的 Node 上运行。
- Controller Manager:
- 负责管理 Controller, 监控集群状态,努力使实际状态与期望保持一致(比如,一个Pod挂了,他就会启动一个新的Pod来替代他)
K8s 还创建了一个 Virtual Network, 覆盖了 Control Plane 和 Worker Nodes 之间的所有通信。使得 Cluster 中的所有 Pods & Services 可以在一个Flat Network中相互通信,即使它们在不同的物理机器上。
Kubernetes Configuration & YAML
如何告诉 K8s 我们要运行什么应用?
- 用
API Server来交互 - 用
YAML文件来Declaratively描述我们期望的状态(Desired State)

我们管 K8s 的 YAML 文件叫做 Manifest.
一般包含几个顶级字段:
apiVersion: 使用的 K8s API 版本kind: 要创建的资源类型 (Pod, Service, Deployment, etc.)metadata: 资源的名字、namespace、labels等spec: 最重要的部分 - Desired State. (比如 replicas: 3, image: nginx:latest, ports: [80, 443], etc.)status: 当前实际状态。由 K8s 自动维护。
当你用 kubectl apply 命令提交这个 YAML 文件后,Kubernetes 就会努力让“实际状态”去匹配你的“期望状态”。然后你通过 status 字段来查看“实际状态”,比如是不是真的有3个副本在运行。
在本地学习测试K8s,我们可以使用 minikube 来创建一个单节点的 K8s Cluster,然后使用 kubectl (K8s CLI, 去沟通Control Plane的API Server) 来管理它。
Lecture 5 : Kubernetes 2
K8s 有很多组件,之前学了 Nodes 和 Pods,现在学一下其他几个关键组件:
- Namespace: 一个 Cluster 可以包含多个 Namespace, 每个 Namespace 是 Cluster 中的一个逻辑隔离区域。
- Deployment: 管理
无状态(Stateless)的应用程序。 - StatefulSet: 管理
有状态(Stateful)的应用程序 (比如数据库)。 - Service: 用于Pod之间的通信以及
负载均衡(Load Balancing)。 - Volume: 用于持久化数据 (Persistent Data)。
- ConfigMap: 用于存储配置文件。
- Secret: 用于存储敏感信息 (Sensitive Data) (比如密码)。
- Ingress: 用于将集群内部的服务暴露(expose)给外部访问。
我们几乎从不直接创建 Pod, 比如去写一个 kind: Pod 的YAML file.
我们使用更高层次的抽象,比如 Deployment(部署)或 StatefulSet(有状态集).
因为 Pod 是“脆弱的”。如果一个 Pod 崩溃了,它就死了,不会自动回来。这不符合我们对健壮系统的要求。
而:一个 Deployment 会管理一组 Pod. 你在 Deployment 的 spec 中说“ 我想要3个副本”. Deployment 的控制器 (Controller) 就会去创建3个 Pod。如果其中一个 Pod 崩溃了,控制器会立刻发现,并马上启动一个新的 Pod 来替代它。
这个是 Kubernetes 的核心价值: Self-Healing & Maintaining Desired State.
State, Storage & Configurations
上面提到了,我们有两种基本的应用类型:
- Stateless(无状态) -
Deployment:像我们之前做的那个电影网站。它只是读取数据,本身不存储任何变化。这种应用非常容易扩展,用 Deployment 就行。我可以轻松地把它从3个副本扩展到100个。 - Stateful(有状态) -
StatefulSet:比如数据库。每个数据库实例的数据可能不一样(比如主库和从库),它们需要把数据�持久化地存储在某个地方,而且它们有自己独一无二的身份(比如 db-0, db-1)。
Volumes: 用于持久化数据 (Persistent Data)
我们之前讲过,Pod 是 ephemeral (短暂的),它重启后,里面所有的数据都会丢失。如果这是个数据库 Pod,那数据就全没了。所以,我们必须把数据存储在 Pod 之外。这就是 Volumes 的作用。
在 Kubernetes 中,存储是这样工作的:
- PersistentVolume (PV):持久卷。这是集群管理员提前准备好的“一块存储”,比如一块 AWS EBS 云硬盘,或者只是节点上的一个目录。
- PersistentVolumeClaim (PVC):持久卷
声明。这是一个用户(或 Pod)发出的“存储申请”。它说:“我需要 10GB 的存储空间”。
Kubernetes 会自动把符合条件的 PV 和 PVC 绑定(bind)在一起。
StatefulSet 就会为它的每个 Pod 自动创建并管理一个 PVC,确保每个 Pod 都有自己独立的、持久化的存储空间。
ConfigMaps & Secrets
解决了数据存储,那应用的配置呢?比如数据库的 URL、用户名、密码。我们不应该把这些信息硬编码在 Docker 镜像里。
ConfigMap 和 Secret 就是用来解决这个问题的。
- ConfigMap: 用于存储非敏感信息 (Non-Sensitive Data) (比如配置文件), 他们是
纯文本的。 - Secret: 用于存储敏感信息 (Sensitive Data) (比如密码), 他们是默认是用
Base64 编码的- 注意:Base64 不是加密,只是编码。但在一个生产集群里,它们应该被配置为“静态加密”(Encryption at Rest)。
那么 Pod 如何使用它们呢?有两种主要方式:
- 注入为
环境变量(Environment Variables)。 - 挂载为
卷文件(Volumes)。ConfigMap 或 Secret 里的每一个键值对,都会在 Pod 里变成一个文件。
StatefulSet 管理 Pod,去叫 Pod 使用 Volume (在 Pod 的 spec 字段中声明它要 mount 哪个 Volume), 而 Volume 里面填了 ConfigMap 或 Secret.
当然最后Pod使用的主要方式也说了,不一定要填到 Volume 里面,也可以直接注入为环境变量。
Networking
Pod 的第一个问题:数据存储和应用配置解决了。
第二个问题是:Pod 不仅仅是ephermal的,它的 IP Address 也是 ephemeral 的。这就意味着,如果一个 Pod 重启了,它的 IP Address 就会改变。
那么,如果我的前端 Pod 需要和后端 Pod 通信,它需要知道后端 Pod 的 IP Address。这就需要一个Service来解决 (在 Lecture 5 开篇的第4点有提到)。
Services
Service 是 Kubernetes 网络的核心。你可以把它想象成一个“前台接待”或“稳定的门牌号”。
它的作用是:
- 提供一个稳定的 IP 地址:Service 会被分配一个它自己的、永不改变的内部 IP(叫做
ClusterIP)。 - 服务发现:Service 使用
Labels (标签)和Selectors (选择器)来自动发现它应该管理哪些 Pod - 负载均衡(Load Balancing):当请求到达 Service 的 IP 时,它会自动把请求转发给背后某一个健康的 Pod 副本,实现负载均衡。
- 在 Deployment 的 template (YAML file 中的
spec字段) 里,你给 Pod 打上标签:labels: { app: my-app } - 在 Service 的 YAML file 中,你又会指定要使用哪个标签来选择 Pod:
selector: { app: my-app }
这�样,Service 就会自动找到所有匹配这个标签的 Pod,并把它们作为后端,实现负载均衡。
Ports
在定义 Service 时,你会遇到好几个“port”,这非常容易混淆:
- targetPort: 目标端口。这是你的容器(Container)真正在监听的端口。比如你的 Node.js 应用运行在 8000 端口。
- port: 服务端口。这是
Service在集群内部暴露的端口。集群内的其他 Pod 应该通过http://<service-name>:<port>(例如http://my-service:80) 来访问它。 - nodePort: 节点端口。这是 Service 在每个
Node 节点(物理机/虚拟机)上暴露的端口,通常是一个30000-32767之间的高端口。它允许你从集群外部通过http://<node-ip>:<nodePort>来访问服务。我们在 Lab 4 中就会用它。
Ingress (入口) - 更智能的路由
NodePort 虽然能从外部访问,但它不灵活(只能用高端口)且不适合生产环境。
更高级的方案是 Ingress。Ingress 是一个 L7 (HTTP/HTTPS) 路由规则管理器。它可以帮你实现:
- 基于域名(domain name)的路由:
api.example.com转发到api-service;www.example.com转发到web-service。 - 基于路径(path)的路由:
example.com/api转发到api-service;example.com/转发到web-service。
Ingress 资源本身只是一套规则。你还需要一个 Ingress Controller(如 NGINX Ingress Controller 或 AWS ALB)来执行这些规则。
补充: Namespace
K8s 也有 Namespace 的概念,用于隔离资源。
你可以用 kubectl get pods -n dev 来只看 dev 空间里的 Pod,用 kubectl get pods -n prod 来看 prod 里的。这对于组织大型团队和隔离资源非常有用。
Lecture 6 - 好像算是拓展 / 复习?
一、Stateful? Volume / PV / PVC
首先要问一个问题:为什么应用需要Stateful?
我们知道,Pod 被设计为临时的(Ephemeral) 。K8s 随时可能因为节点故障、负载均衡或更新而杀死并重建一个 Pod。当一个 Pod 被销毁时,它在容器读写层 (R/W layer) 中的所有数据都会永久丢失。
核心概念
- Volume:本质是“存放数据的地方”,可在容器运行时挂载到文件系统中的某个挂载路径(mountPath)
- PersistentVolume (PV):持久卷。集群里
真实存在的一块存储资源, 比如一块AWS EBS 云硬盘,或者只是节点上的一个目录。 - PersistentVolumeClaim (PVC):持久卷声明。Pod 需要使用存储时,通过 PVC 向管理员申请一块 PV。对存储的请求(申请 N Gi、访问模式等)。常用
ReadWriteOnce(单节点读写,但可被该节点上的多个 Pod 使用)。
在 Minikube 场景:常用 hostPath 做演示;云上会用 EBS/NFS 等专业后端。
二、ConfigMap & Secret
- Non-Sensitive Data: ConfigMap
- K/V 存储,纯文本
- 以
环境变量或卷文件挂载两种方式注入 Pod - 不要放敏感数据!!!
- Sensitive Data: Secret
- 定义格式与 ConfigMap 类似,但用
base64编码 - 真正生产需要开启
静态加密(Encryption at Rest)(EKS 可以用KMS实现)
- 定义格式与 ConfigMap 类似,但用
- 环境变量:
简单键值、应用天然读 env 的场景(如 AWS_ACCESS_KEY_ID)。 - 卷挂载:
内容较大/文件形(证书、JSON、properties)、上线后可热更新更灵活。
三、Networking
为什么需要副本与服务(Replication & Service)?
- HA(High Availability)高可用 /
容灾(Disaster Recovery):某个 Pod 挂了,流量自动切去健康副本。 - 可伸缩(Scalability):负载上来就多副本 +
负载均衡(Load Balancing)。
Service: 给一组易失的 Pod 提供稳定的虚拟 IP/主机名(反向代理),并且健康检查+负载均衡是“顺带的好处”。
ClusterIP: 仅集群内可达(默认)NodePort: 在每个节点开放一个端口以供外部访问(教学/开发常用;生产更推荐 Ingress)
-
containerPort:容器里应用监听的端口。这是你的容器(Container)真正在监��听的端口。比如你的 Node.js 应用运行在 8000 端口。
-
targetPort: 目标端口。Service 把流量转发到 Pod 的哪个端口(应等于 containerPort)
-
port: 服务端口。这是
Service在集群内部暴露的端口。集群内的其他 Pod 应该通过http://<service-name>:<port>(例如http://my-service:80) 来访问它。 -
nodePort: 节点端口。这是 Service 在每个
Node 节点(物理机/虚拟机)上暴露的端口,通常是一个30000-32767之间的高端口。它允许你从集群外部通过http://<node-ip>:<nodePort>来访问服务。
四、Ingress (入口)
云负载均衡的两类:
- ALB(应用型,L7):按
URL/Host/Header做转发规则 - NLB(网络型,L4):不看报文内容,只做转发
本课使用 Ingress 时,通常配 ALB(或本地用 NGINX Ingress 模拟)。
Ingress 与 Ingress Controller
- Ingress:描述“域名/路径 → 集群内 Service”的路由
规则 - Controller:
读取规则并实际执行。- AWS ALB:EKS 自带,无需安装;较慢但原生对接云 LB。
- Ingress-NGINX:需自己安装,CSP 无关,Minikube 可用,部署快。(两者通过注解区分 class)。
域名如何指向 Ingress?
在域名提供商处配置 DNS 记录(A/AAAA/CNAME),把域名指到云 LB 的地址;Ingress 规则再把请求分发到后端 Service。

Lecture 7
一、Namespace 回顾
Namespace 是把单个物理集群“逻辑分区”的办法,便于隔离(如 dev / prod)、权限与资源配额管理。
可以给不同的命名空间设置CPU配额(Quota) (比如 2 vCPU) / 内存配额(Memory Quota) (比如 4GB) 与副本数上限/下限 (比如 1-10个 Pod)
二、让 Kubernetes “可上生产”的关键:自动扩 / 缩容(Autoscaling)
Horizontal Pod Autoscaler (HPA)
-
HPA 是 Kubernetes 的自动扩 / 缩容机制,它会基于平均资源使用百分比阈值,自动增加/减少副本数。常见字段:
minReplicas、maxReplicas、targetCPUUtilizationPercentage。 -
HPA 的度量(Metric)来自
metrics-server,它会定期采集 Pod 的 CPU 和内存使用情况,然后计算出平均使用率。Minikube 需要启用addon才能使用。
Vertical Pod Autoscaler (VPA)
自动调整 Pod 的 CPU配额 / 内存配额;有时需要重启容器才能生效(因此对“不能轻易重启”的应用要谨慎)
Requests / Limits 易混点
- Requests:容器运行时所需的最低资源量(HPA 会基于此调整副本数)
- Limits:容器运行时可使用的最大资源量(超过会 OOMKilled)
三、Kubernetes 中的“任务”调度:Job & CronJob
Job vs CronJob
- Job:
一次性任务,运行到容器退出即完成;可设重试/backoff。适合恢复备份、建管理员、初始化数据等。 - CronJob:按 cron 表达式
周期性创建 Job;无需手动触发。
Cron 表达式速览
分钟 小时 日期 月份 星期
* * * * *
0 * * * * 表示每小时的第 0 分钟执行一次。*/10 * * * * 表示每小时的第 0, 10, 20, 30, 40, 50 分钟执行一次。
0 0 * * * 每天 0 点;0 0 * * 0 每周日 0 点;0 0 1 * * 每月 1 日 0 点。
CronJob 示例
将调度从“每 5 分钟” 改到 “每 1 分钟”,用kubectl describe cronjob <cronjob-name> 查看调度信息, Last Scheduled Time 每分钟刷新。
总
Lecture 1:Intro(云计算基础、FastAPI Lab)
必背要点
- 三层服务模型:SaaS / PaaS / IaaS:定义、谁维护什么、常见例子与边界;对比自建与上云的优劣(弹性、成本、维护)。
- Hybrid vs Multi-Cloud 场景与动机(成本/安全、避免厂商锁定)。
- Serverless(不是没服务器,是免运维;按执行次数计费)与 Edge Computing(贴近数据源降时延)。
- 容器(Docker 的打包与可移植性)与编排(Kubernetes 的自动部署/伸缩/调度)的一句话定位。
- Lab1/FastAPI 基础:CRUD 概念;路由/endpoint;Jinja2Templates 渲染 HTML;TemplateResponse 需要 request; 读本地 JSON 并传入模板。
易错/陷阱
- 混淆 Serverless 与 PaaS;误以为 Serverless = 无限免费 or 无冷启动。
- 忘记 S3/存储类服务不等于“整个平台”;SaaS/PaaS/IaaS 边界题常混淆。
- FastAPI 模板渲染少 request 参数导致渲染失败。
可能出题方式
- 选择/填空:给描述判定 SaaS/PaaS/IaaS。
- 判断:Serverless 的计费与“免运维”说法是否正确。
- 简答:Hybrid vs Multi-Cloud 的动机。
- 读码题:指出 TemplateResponse 少传 request 的问题;解释 get_users_data() 返回什么、如何传入模板。
Lecture 2:Cloud Storage、S3、访问控制与 Boto3
必背要点
- 云存储动机(本地硬件的贵/不灵活/难扩展)与三大厂的对象存储
- S3 核心:Bucket / Object / Key(基于键的存储,非树型);Bucket 名称全局唯一
- RBAC 与最小权限原则(PLP):按角色授予最少权限;审计(CloudTrail);临时凭证(STS)
- IAM 组件:Policy/Permission/Role/User/Instance Profile;外部访问(AK/SK)vs 内部访问(EC2 角色)
- Boto3 概念:Resource(高阶)/Client(低阶)/Session/Waiters(等待异步完成)/Paginators(自动分页)
- Lab2:从 S3 读 JSON,替代本地文件
易错/陷阱
- 直接给用户长期 AK/SK;在 EC2 里不用 Role
- 混淆 Resource 与 Client;忽视 Waiter 造成竞态/半成品资源
- 把 S3 当成本地层级文件系统来用(Key 只是字符串路径)
可能出题方式
- 场景题:给你"只读某 Bucket 某前缀"的需求,如何设计角色与 Policy 以符合 PLP?
- 选择:Bucket 名称是否全局唯一、S3 是否树形结构
- 读码:s3.Object(bucket, key).get()['Body'].read() 解释数据流;指出缺少分页/等待器隐患
- 简答:内外部访问凭证的最佳实践差异
Lecture 3:VM & Containers、Docker 基础与 Buildx
必背要点
- VM vs Container:
- 虚拟化层级:VM=硬件层,Container=OS 层
- 资源分配:VM 固定/偏大,Container 默认无限制更高效
- 隔离/安全:VM 完全隔离更安全;Container 共享内核更轻量
- GUI/跨OS:VM 更灵活,容器共享内核受限
- Hypervisor:Type-1(裸金属,云厂商常用)vs Type-2(宿主 OS 上)
- Linux Namespace 类型:PID/net/mount/IPC/uts/user;unshare 创建隔离视图
- Docker 核心:
- Image = 多个只读层;Container = 镜像层之上的可写层
- Dockerfile 指令:FROM/COPY/RUN/CMD
- 常用 CLI:build/run/ps/exec -it;端口映射 -p host:container
- 发布:tag/login/push
- Buildx 多架构构建与 --platform linux/amd64,linux/arm64;--load 切回本地单平台工作流
- Lab3:容器内访问 S3 需用环境变量提供 AK/SK(对比 Lab2 的 EC2 Role)
易错/陷阱
- 误以为 Docker 自带内核;把 Layer 和 Namespace 混为一谈
- 容器端口日志始终显示容器内端口(命名空间视角),与宿主机映射端口不同
- 在生产把长期 AK/SK 烧进镜像
可能出题方式
- 对比题:列 3 点 VM vs Container
- 选择:哪个属于 Image 层变化、哪个属于 Container 层?
- 命令题:写出多平台镜像构建并推送到 Hub 的命令
- 判断:Docker 是否包含内核;docker exec -it 作用
- 场景:为何在 EC2 上 Lab2 不需要 AK/SK 而 Lab3 需要?
Lecture 4:Kubernetes(动机、架构、YAML)
必背要点
- Docker 不包含内核;Namespace 是隔离机制;Layer 只是被隔离的文件系统内容(mount)
- 为何需要 K8s:高可用、容错、可伸缩、状态管理、分布式资源抽象
- 架构:
- Control Plane:API Server(唯一入口)、etcd(状态存储)、Scheduler(调度)、Controller Manager(控制循环)
- Node 与 Kubelet
- Pod=最小部署单元、短暂、可被替换;集群虚拟网络"扁平互通"
- YAML/Manifest:apiVersion/kind/metadata/spec/status;kubectl apply 以声明式驱动"期望态=实际态";minikube + kubectl 本地练习
易错/陷阱
- 直接创建 Pod 不用更高抽象(Deployment/StatefulSet)
- 把 status 当成自己填写;忽略 labels/selector 在后续对象中的作用
可能出题方式
- 填空:控制面 4 大组件与职责
- 简答:声明式 vs 命令式,有何优势?
- 读 YAML:指出该清单缺失的关键字段或 labels 导致的后续联动问题
- 命令题:本��地用 minikube 部署 manifest 的步骤
Lecture 5:Kubernetes 进阶(工作负载、存储、配置、网络)
必背要点
- 对象族谱:Namespace / Deployment(无状态)/ StatefulSet(有状态)/ Service / Volume / ConfigMap / Secret / Ingress
- 为什么 Deployment 而不是裸 Pod:自愈 + 期望副本数
- 存储:PV(管理员准备的真实存储)/ PVC(用户申请);StatefulSet 为每个 Pod 管理独立 PVC
- 配置:ConfigMap(非敏感,纯文本);Secret(敏感,base64,生产需静态加密)。注入方式:环境变量或挂载为文件
- 网络:Pod IP 易变 → Service 提供稳定访问点;通过 label/selector 绑定后端 Pod 并负载均衡
- 端口语义:containerPort(容器监听) = targetPort(Service 转发目标);port(Service 暴露给集群内部);nodePort(对外部主机高端口)
- Ingress:L7 路由(基于域名/路径);需 Ingress Controller(如 NGINX 或云厂商 ALB)
易错/陷阱
- 把 Secret 当"加密";base64 不是加密
- 搞混 port/targetPort/nodePort/containerPort
- Service 不写 selector 或标签不�匹配,导致流量落不到后端
可能出题方式
- 画关系:Deployment↔Pod↔Service 的 label/selector 连接
- 选择:哪个场景用 StatefulSet;PV/PVC 角色分工
- 配置设计:把 DB 凭证以何种方式注入?说明取舍
- 端口配对题:给一组数值,让你标注各字段
Lecture 6:状态、配置与流量入口的串讲("要点速记"风格)
必背要点(速记版)
- Stateful & 存储:Pod 短暂 → 数据需落盘;PV(供给)/PVC(申请);常用访问模式:ReadWriteOnce(同一节点多 Pod 可用)
- ConfigMap / Secret:env 简单键值;卷挂载适合证书/大文件/热更新;Secret 要静态加密(EKS 可配 KMS)
- 副本与 Service:HA/容灾/扩缩容;Service = 稳定 IP + 负载均衡 + 健康探测
- 端口四兄弟:containerPort(=目标端口)/targetPort/port/nodePort
- Ingress:ALB(NLB 对比);域名 → LB → Ingress → Service;DNS 记录(A/CNAME)指向 LB
可能出题方式
- 连线题:端口语义配对
- 场景:把 api.example.com 与 www.example.com 路由到不同后端,画出 Ingress 规则与 Service
- 简答:为何生产更偏向 Ingress 而非 NodePort?
- 解释:为何 R/W 层数据在 Pod 重建后会丢失,如何避免?
Lecture 7:Namespace、自动扩缩与定时任务
必背要点
- Namespace:逻辑隔离;可配置CPU/内存配额与副本数上下限,配合 RBAC 实现多租户/环境隔离
- Autoscaling:
- HPA:按平均资源使用率自动调副本数(需 metrics-server);公式:
replicas = ⌈current replicas × (current value / desired value)⌉ - 常用字段:minReplicas / maxReplicas / targetCPUUtilizationPercentage
- HPA:按平均资源使用率自动调副本数(需 metrics-server);公式:
- VPA:自动调 requests/limits(可能需重启)
- Requests vs Limits:最低保证 vs 上限(超限 OOMKilled)
- Job / CronJob:
- Job 一次性任务,支持重试/backoff
- CronJob 周期性创建 Job;Cron 表达式:分 时 日 月 周
易错/陷阱
- 把 HPA 当"按 QPS 扩容"而忘了它默认依据 CPU/内存(可扩展自定义指标)
- 只调 Limits 不调 Requests,HPA 失真;或把 VPA 与 HPA 冲突使用不加策略
- Cron 字段顺序写反;Job 与 CronJob 的"谁生成谁"关系搞错
可能出题方式
- 计算题:给 desired=50%,当前=120%,当前副本=5,问扩到多少
- 判断:VPA 是否总是即刻生效?Requests/limits 的作用分别是什么?
- Cron 题:把"每周日零点执行"写成表达式并解释
- 命令/诊断:如何在 minikube 启用 metrics-server 以让 HPA 工作;如何查看 CronJob 的 Last Scheduled Time