Clustering -- k-Means&Hierarchical Clustering
Clustering: k-Means&Hierarchical Clustering
Review
我们有两种学习方法to learn from data:
- Supervised Learning: 数据有label - Regression / Classification
- Unsupervised Learning: 无label -
聚类
Clustering
Intro
Two main principles:
- Maximize similarity within clusters
- Minimize similarity between clusters
And clustering can help us to:
- Discover structure in data
- Make labeling easier
Validation:
- 使用一些已知的标签
- 观察能否得到有意义的新结构
Hierarchical Clustering
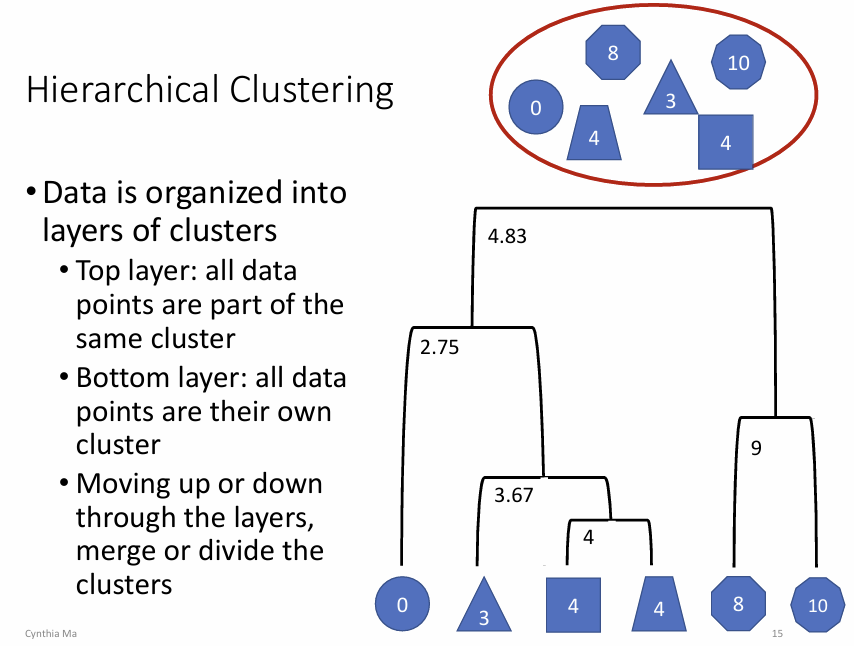
Merge的��依据是 距离。
一些专业术语
- Agglomerative: 自底向上
- Divisive: 自顶向下
- Dendrogram: 树状图。展示聚类过程,可以从不同高度“剪断”来确定簇数
- Heatmap: 热力图。展示数据的相似性
Agglomerative Algorithm
-
定义距离的函数:
- Manhattan distance
- Euclidean distance
- Hamming distance
-
定义比较方法:
- Centroids: 计算每个簇的中心点,比较中心点之间的距离(i.e. 簇均值的距离)
- Single Linkage: 计算每个簇中
最接近的两个点之间的距离 - Complete Linkage: 计算每个簇中
最远的两个点之间的距离
-
每个点初始化为一个簇,找到
最相近的两个簇(所以无论第2步是哪种方法,都是要找最小值哦 - 最远的两个点也是越��近越好),合并它们。重复这个过程,直到所有点都在一个簇中。
Divisive Algorithm
-
定义
Spread的metric:- Average Euclidean distance from the centroid
- Maximum Hamming distance within the cluster
-
选择Spread最大的簇,分裂成两个簇。拆法:
- 定义两个新的centroid,然后allocate每个点到离它最近的那个centroid

要够闲就读一读伪代码..)
!! k-Means Clustering
- 指定k个簇数
- 随机选择k个点作为初始centroid
- E-step: 分配每个点到离它最近的centroid
- M-step: 计算每个簇的均值,作为新的centroid
- 重复3-4,直到centroid不再变化
特点:
- 每一步都使得
簇内平方误差(Sum of Squared Errors, SSE)减少 - 计算复杂度低,适合大数据集,速度快
- 但!!
- 对初始centroid敏感
- 只能发现凸形簇(convex clusters)以及大小相似的簇
为了解决对初始centroid敏感的问题,我们一般multi-starts:
每次随机初始化k个centroid,选择SSE最小的结果。
--> 减少陷入局部最优的风险
如何选出最理想的k?
k增加的时候,Spread会减小。
不过曲线如图:
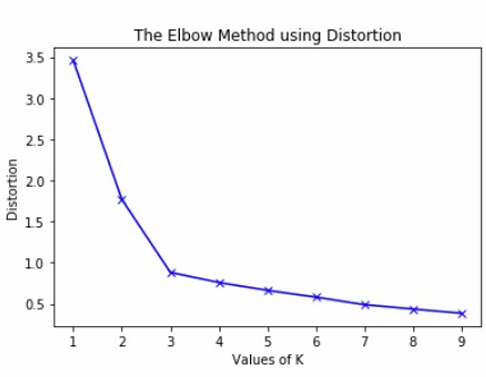
所以我们用Elbow Method来选出最理想的k - 即选择拐点处的k。这样不浪费性能也保证Spread够小
EM Clustering with Gaussian Mixture Models (GMMs)
- 假设数据是由 k 个高斯分布(normal distribution)混合而成
- 每个样本属于每个高斯分布的“概率”不同 -> 软分配(soft clustering)
- 初始化高斯参数(均值、协方差矩阵、权重)
- E-step:对每个样本,计算属于每个簇的“概率”
- M-step:根据这些概率,更新每个簇的参数(相当于重新拟合分布)
- 重复直到收敛
GMM vs k-Means
跟GMM对比的时候,k-Means最适用的凸形簇场景可以直接具体为球形簇。
而GMM可以处理椭球形簇,而且可以处理不同大小的簇。