KDD & Data Characterization
一些散的知识点
pre-processing
- Data Cleaning
- Data Integration
- Data Selection
- Data Transformation
Characterizing Data
- Data type: quantitative, qualitative, or a complex mix
- Size of dataset
- Data dimensionality
- Quality of data: presence of missing, erroneous, or redundant values
Data type
Quantitative / Numerical (定量的) [一级形容]
- Number
- Distance between values is meaningful
- Discrete: Integers (离散的)
- Continuous (连续的) [二级形容]
Qualitative / Categorical
- Names, labels, or categories
- Distance between values is not meaningful
- Nominal: cannot be sorted
- Ordinal: ordering is meaningful
eg. Height is a Quantitative Continuous variable.
Numerical Encoding of Categorical Features (定性数据的定量编码)
- One-hot:
Create a binary column for each unique category/value. Place a 1 in the column for the relevant category, and a 0 in all others. - Dummy:
Same as one-hot, but drop one of the columns. 【避免了线性依赖在线性模型中带来的影响】
//------------------
- Binary:
Only True/False, 1/0.
//------------------
- Ordinal:
Assign numerical values based on natural ordering, starting with 1 (sometimes starting with 0) - Label:
Each unique category/value is assigned a unique integer that does not reflect any ordered relationship.
NOTE: Uppon two are both sometimes referred to as "Integer encoding"
//------------------
- Target:
Average value.
Curse of Dimensionality
What is "BIG" data?
-
A data point is a single object or sample in your set.
-
The dimensionality is the number of features.
-
Complex mix of data and data types.
简单来说:
1. 数据点代表的单位小 -> 数据量大
2. 特征多 -> 维度高
3. 复杂
=> 大数据
Curse of Dimensionality
维度诅咒 (Curse of Dimensionality) 是指随着数据特征(维度)数量的增加,数据分析和模型训练变得越来越复杂甚至失效的一种现象。
主要体现在:
- 数据稀疏性:高维下,距离↑
- 计算复杂度
- 距离意义失效: 随着维度增加(n变大),无关特征的占比增大。
- 过拟合
Distance Computations
Definition of Norm
In mathematics, a norm is a function f: V → R that satisfies the following properties:
- Positivity:
, for all x in V, and f(x) = 0 if and only if x = 0. - Triangle Inequality:
, for all x, y in V. - Positive Homogeneity:
, for all x in V and α in R.
Which means that once the vector is scaled, the norm is scaled by the same factor.
Distance Metrics
(1-Norm) Manhattan Distance:
其中,x, y是两个点,n则是维度。
例如A(1, 2), B(3, 4)的曼哈顿距离为:
(2-Norm) Euclidean Distance:
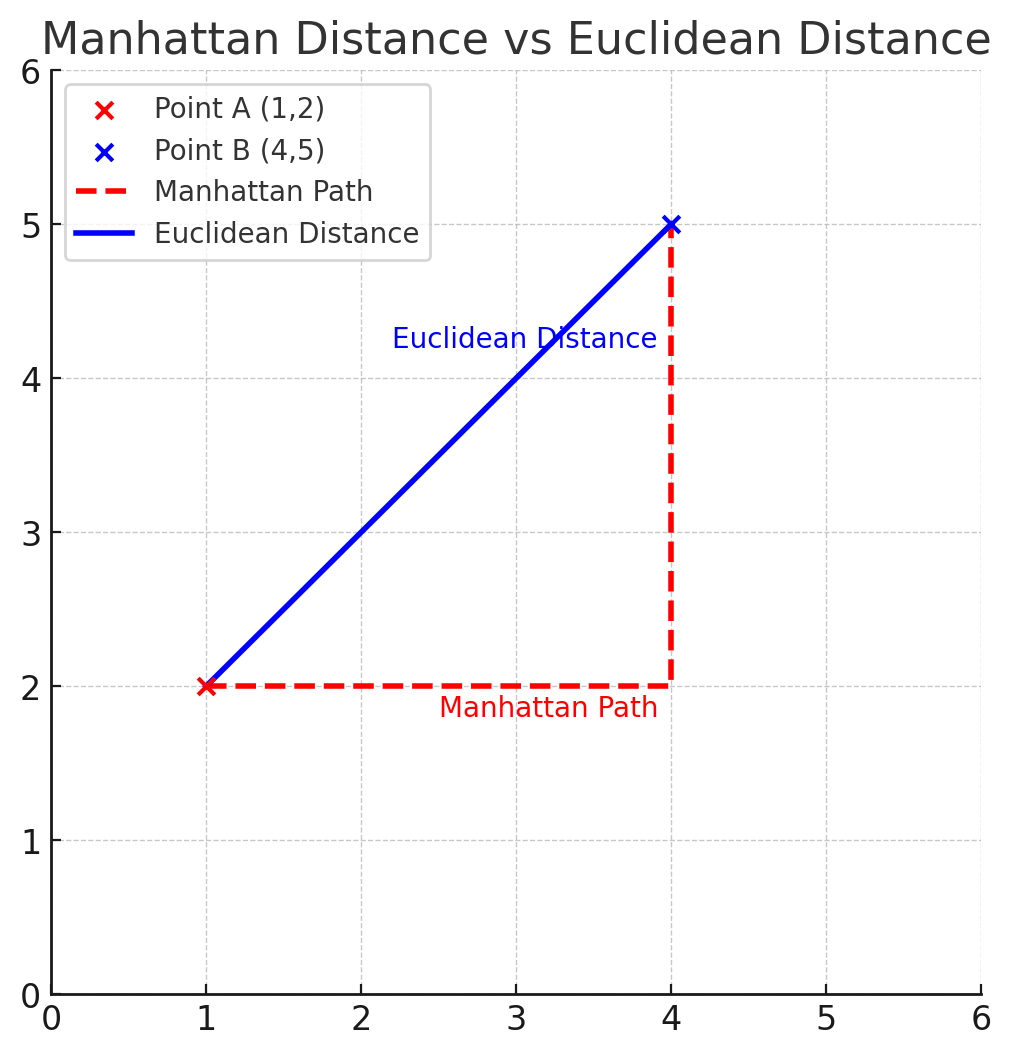
=> 两者都是Minkowski Distance的特例
Minkowski Distance (p-Norm / Lp Norm):
可知,无穷范数(∞-Norm):
这是因为遵守p-Norm的定义,当p趋近于无穷时,范数逐渐接近向量中最大分量的绝对值(指数爆炸嘛)