SVMs and the Kernel Trick
SVM
首先,SVM的目标是找到一个超平面(hyperplane),使得它能将数据分成两类,并且距离超平面最近的点到超平面的距离最大化。
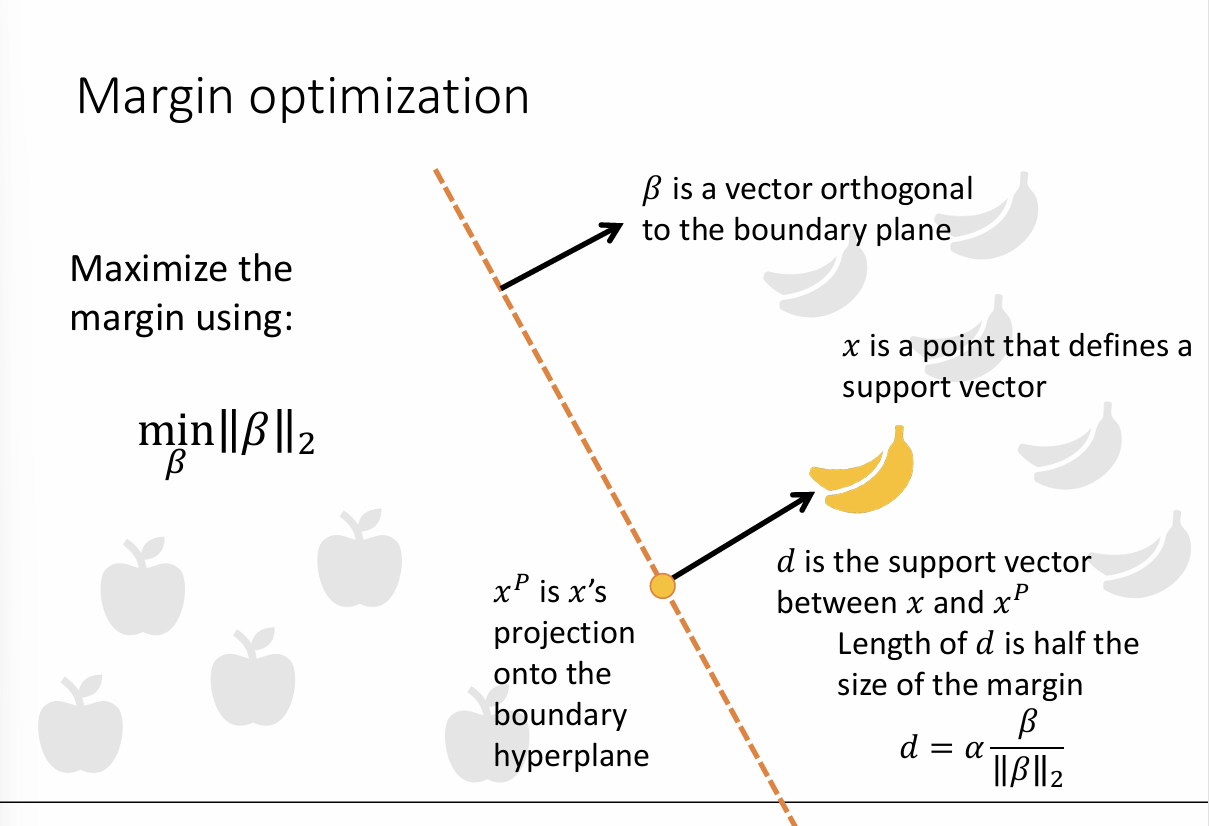
举个具体的例子:
现在我们有一个超平面:
2x1+3x2−6=0
即 β=[2,3], b=−6
(1) 其中一个支持向量位于:x=(4,1)
(2) 所以超平面法向量L2范数(即长度)为:
∥β∥2=22+32=13
(3) 该支持向量到超平面的距离为:
d=132∗4+3∗1−6=135
(4) α:
α 的含义就是 d 的长度, 即 135
(5) 而向量 d :
d=α∣∣β∣∣β=135∗13[2,3]=135∗[2,3]=[1310,1315]
Hinge Loss
介绍一个新loss function:Hinge Loss(合页损失)
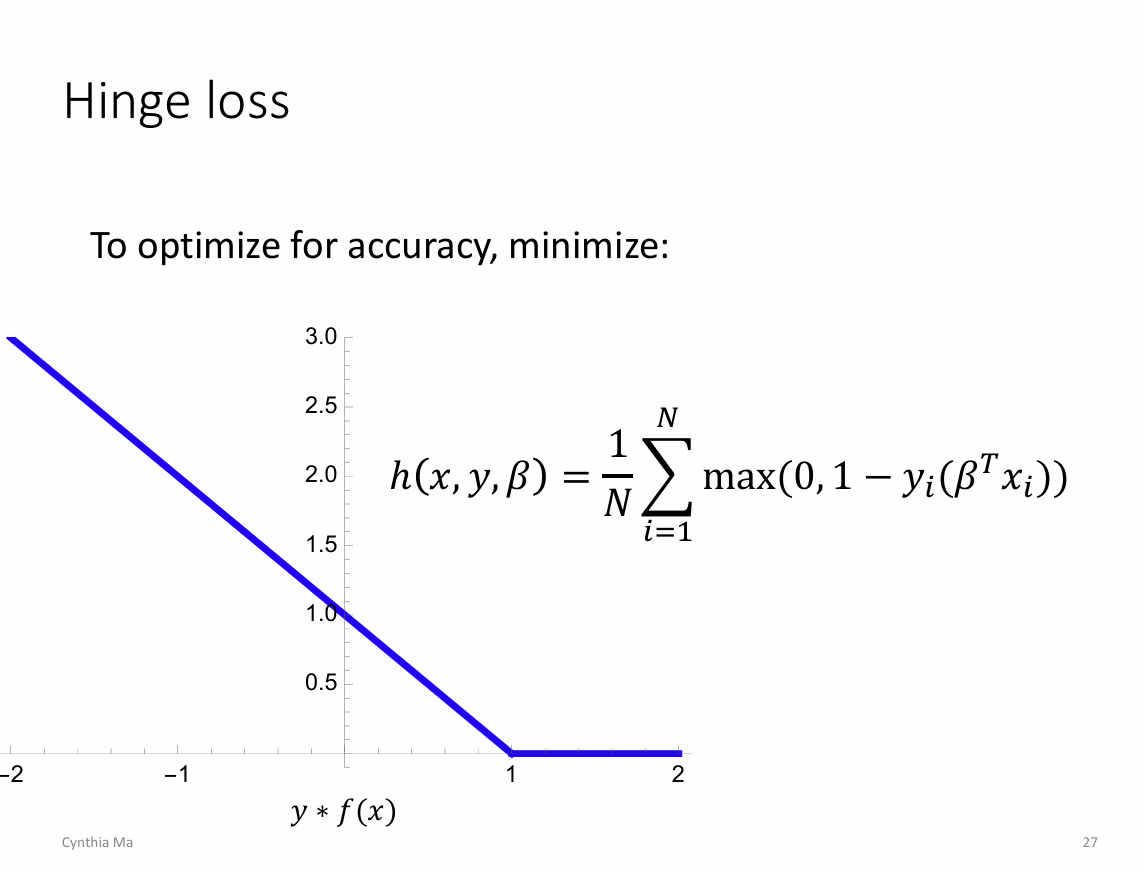
举个栗子:
给定一个样本点 xi, 它的真实标签是 yi=−1, 预测标签是 f(xi)=βTxi=0.5, 那么它的Hinge Loss为:
h(x,y,β)=max(0,1−yif(xi))=max(0,1−(−1)∗0.5)=1.5
你看,如果预测值不是0.5而是-1.2,那么Hinge Loss就是0了。
所以:
- yi(βTxi)≥1, Hinge Loss = 0 -> 分类足够好,不需要优化
- yi(βTxi)<1, Hinge Loss > 0 -> 损失增大,迫使调整边界,提高分类精度
所以HL才适用于SVM,因为优化目标就是最大化边界。
Math Optimization
To balance between maximizing accuracy and maximizing margin, fit the hyperparameter Λ:
SVM loss function:
βmin∥β∥2+λh(x,y,β)
Gradient Descent优化推导:
上面式子拆开来:
=>βmin∥β∥2+λN1i=1∑Nmax(0,1−yiβTxi)
=>βminN1i=1∑N[ ∥β∥2+λmax(0,1−yiβTxi) ]
那最后对 β 求偏导:
∂β∂=N1i=1∑N{β,β−λyixi,1−yi(βTxi)≤0otherwise
厉害的来了!! Dual problem optimization
不管别的,总之SVM问题是strong duality的:
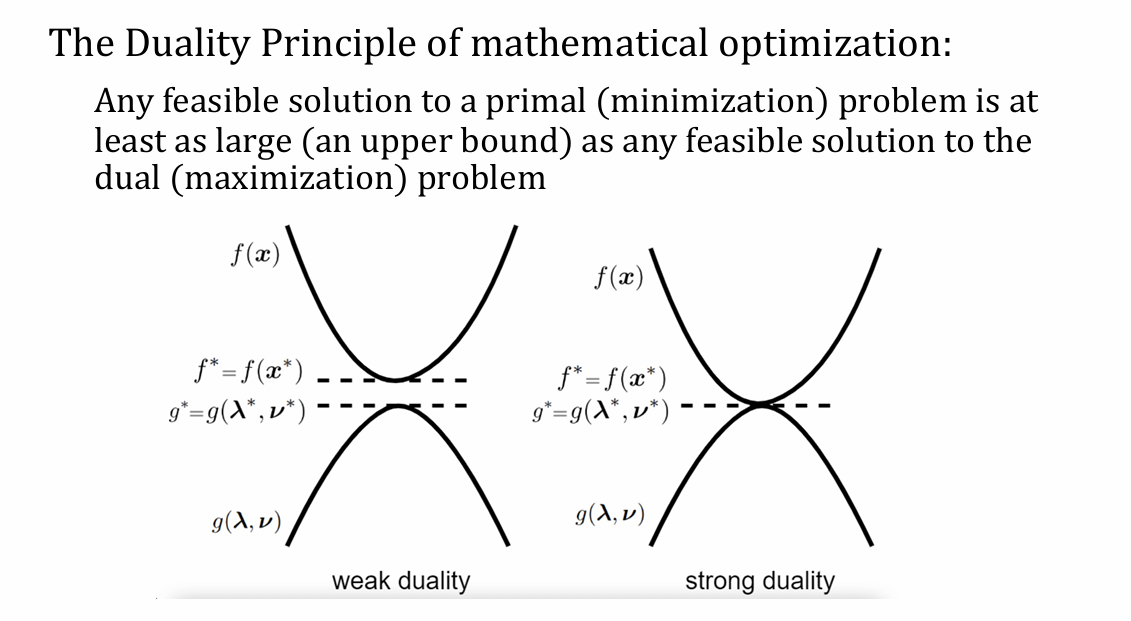
所以求maximizing accuracy和求maximizing margin(i.e. minimizing ∥β∥2)是等价的。
拉格朗日乘子
拉格朗日乘子法将约束问题转化为无约束问题。
目前,我们的约束是:
yi(βTxi+b)≥1
为了消除这个约束,我们引入拉格朗日乘子 αi≥0来代表这个约束的惩罚程度。
于是我们有拉格朗日函数:
L(β,b,α)=21∥β∥22−i=1∑Nαi[ yi(βTxi+b)−1 ]
将原问题变换成对偶问题
SVM采用拉格朗日对偶性来求解,即我们需要先对 β 和 b 求最小,再对 α 求最大。
- 对 β:
∂β∂L=β−i=1∑Nαiyixi=0
=>β=i=1∑Nαiyixi
- 对 b:
∂b∂L=−i=1∑Nαiyi=0
=>i=1∑Nαiyi=0
- 将 β=∑_i=1Nαiyixi 代入 L(β,b,α), 得到对偶问题:
αmaxi=1∑Nαi−21i=1∑Nj=1∑NαiαjyiyjxiTxj
线性不可分?
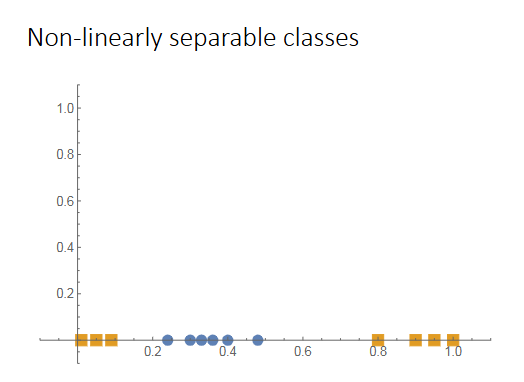
Q: 碰到上图中这种非线性可分的数据点集怎么办?
A:
升维:将数据点升维到高维空间,变成线性可分的kernel trick:直接在低维空间中计算高维空间的内积
讲半天没看懂,直接上实例:
假设现在我们有四个数据点线性不可分:
Sample 1 = (1, -1)
Sample 2 = (3, -1)
Sample 3 = (1.4, 1)
Sample 4 = (2.2, 1)
没法被直线分割,所以我们将它们映射到高维空间去被超平面分割:
定义一个映射:
ϕ(x)=[x2x3]
也就是说 x=1 映射到 ϕ(1)=[1,1], x=3 映射到 ϕ(3)=[9,27]
由于前面我们已经知道了SVM的对偶问题中,无论是 β=∑∗i=1Nαiyixi, 还是最后的对偶问题:max∗α∑∗i=1Nαi−21∑∗i=1N∑_j=1NαiαjyiyjxiTxj,都需要计算 xiTxj。
假如我们的映射函数是100维的,那我们在计算内积 xiTxj 的时候就需要计算100*100=10000次了。
所以我们就要用到kernel trick了:
K(xi,xj)=ϕ(xi)Tϕ(xj)=(si⋅sj+r)d
在这个问题中,r 被设定为1,而 d 则是映射的维度,即2。
也就是说,我们可以通过这种方法近似的计算出高维空间的内积:
K(xi,xj)=(si⋅sj+1)2=16
番外:RBF (Radial Basis Function) kernel
径向基核:
K(xi,xj)=e−γ∣∣si−sj∣∣2
这玩意也简单推一下吧(复习的时候忽略也行我估计..)【被自己骗了...考了呃呃啊啊啊啊!!】:
设定 σ=1/2, 然后展开:
e−21∣∣si2+sj2∣∣esisj
esisj 这玩意无穷级数,占比太大了,基本上RBF kernel就近似等于这一个超高项了。
所以RBF kernel用来处理高度非线性数据集,因为它不局限固定阶数。
要喜欢研究就看吧..
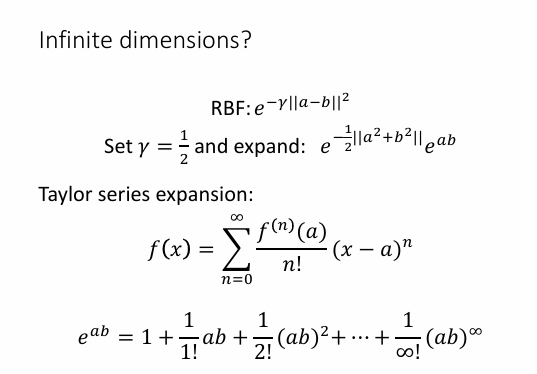
��番外:Multi-SVM
One-vs-One:
- 两两分类,每次选两个类别,训练一个SVM
- n个类别,需要训练 Cn2 个SVM
One-vs-Rest:
- 一个类别对其他所有类别进行分类
- n个类别,需要训练n个SVM